
11.7 MMX Technology Instructions
The following subsections describe each of the MMX instructions in detail. The organization is as follows:
- Data Transfer Instructions,
- Conversion Instructions,
- Packed Arithmetic Instructions,
- Comparisons,
- Logical Instructions,
- Shift and Rotate Instructions,
- the EMMS Instruction.
These sections describe what these instructions do, not how you would use them. Later sections will provide examples of how you can use several of these instructions.
11.7.1 MMX Data Transfer Instructions
movd( reg32, mmi ); movd( mem32, mmi ); movd( mmi, reg32 ); movd( mmi, mem32 ); movq( mem64, mmi ); movq( mmi, mem64 ); movq( mmi, mmi );The MOVD (move double word) instruction copies data between a 32-bit integer register or double word memory location and an MMX register. If the destination is an MMX register, this instruction zero-extends the value while moving it. If the destination is a 32-bit register or memory location, this instruction copies the L.O. 32-bits of the MMX register to the destination.
The MOVQ (move quadword) instruction copies data between two MMX registers or between an MMX register and memory. If either the source or destination operand is a memory object, it must be a qword variable or HLA will complain.
11.7.2 MMX Conversion Instructions
packssdw( mem64, mmi ); packssdw( mmi, mmi ); packsswb( mem64, mmi ); packsswb( mmi, mmi ); packusdw( mem64, mmi ); packusdw( mmi, mmi ); packuswb( mem64, mmi ); packuswb( mmi, mmi ); punpckhbw( mem64, mmi ); punpckhbw( mmi, mmi ); punpckhdq( mem64, mmi ); punpckhdq( mmi, mmi ); punpckhwd( mem64, mmi ); punpckhwd( mmi, mmi ); punpcklbw( mem64, mmi ); punpcklbw( mmi, mmi ); punpckldq( mem64, mmi ); punpckldq( mmi, mmi ); punpcklwd( mem64, mmi ); punpcklwd( mmi, mmi );The PACKSSxx instructions pack and saturate signed values. They convert a sequence of larger values to a sequence of smaller values via saturation. Those instructions with the dw suffix pack four double words into four words; those with the wb suffix saturate and pack eight signed words into eight signed bytes.
The PACKSSDW instruction takes the two double words in the source operand and the two double words in the destination operand and converts these to four signed words via saturation. The instruction packs these four words together and stores the result in the destination MMX register. See Figure 11.3 for details.
The PACKSSWB instruction takes the four words from the source operand and the four signed words from the destination operand and converts, via signed saturation, these values to eight signed bytes. This instruction leaves the eight bytes in the destination MMX register. See Figure 11.4 for details.
One application for these pack instructions is to convert UNICODE to ASCII (ANSI). You can convert UNICODE (16-bit) character to ANSI (8-bit) character if the H.O. eight bits of each UNICODE character is zero. The PACKUSWB instruction will take eight UNICODE characters and pack them into a string that is eight bytes long with a single instruction. If the H.O. byte of any UNICODE character contains a non-zero value, then the PACKUSWB instruction will store $FF in the respective byte; therefore, you can use $FF as a conversion error indication.
Another use for the PACKSSWB instruction is to translate a 16-bit audio stream to an eight-bit stream. Assuming you've scaled your sixteen-bit values to produce a sequence of values in the range -128..+127, you can use the PACKSSWB instruction to convert that sequence of 16-bit values into a packed sequence of eight bit values.
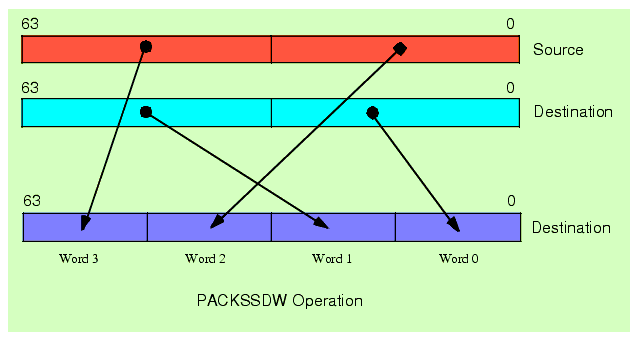
Figure 11.3 PACKSSDW Instruction
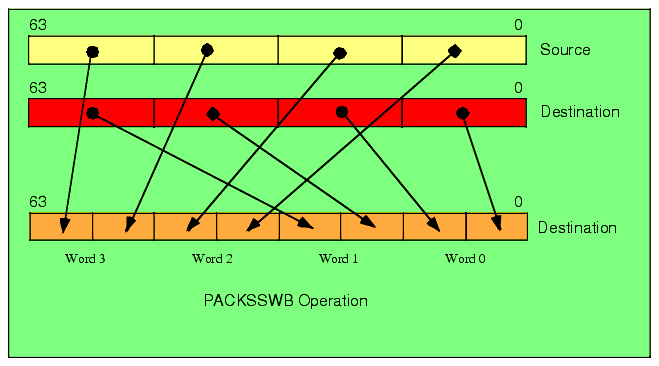
Figure 11.4 PACKSSWB Instruction
The unpack instructions (PUNPCKxxx) provide the converse operation to the pack instructions. The unpack instructions take a sequence of smaller, packed, values and translate them into larger values. There is one problem with this conversion, however. Unlike the pack instructions, where it took two 64-bit operands to generate a single 64-bit result, the unpack operations will produce a 64-bit result from a single 32-bit result. Therefore, these instructions cannot operate directly on full 64-bit source operands. To overcome this limitation, there are two sets of unpack instructions: one set unpacks the data from the L.O. double word of a 64-bit object, the other set of instructions unpacks the H.O. double word of a 64-bit object. By executing one instruction from each set you can unpack a 64-bit object into a 128-bit object.
The PUNPCKLBW, PUNPCKLWD, and PUNPCKLDQ instructions merge (unpack) the L.O. double words of their source and destination operands and store the 64-bit result into their destination operand.
The PUNPCKLBW instruction unpacks and interleaves the low-order four bytes of the source (first) and destination (second) operands. It places the L.O. four bytes of the destination operand at the even byte positions in the destination and it places the L.O. four bytes of the source operand in the odd byte positions of the destination operand.(see Figure 11.5).
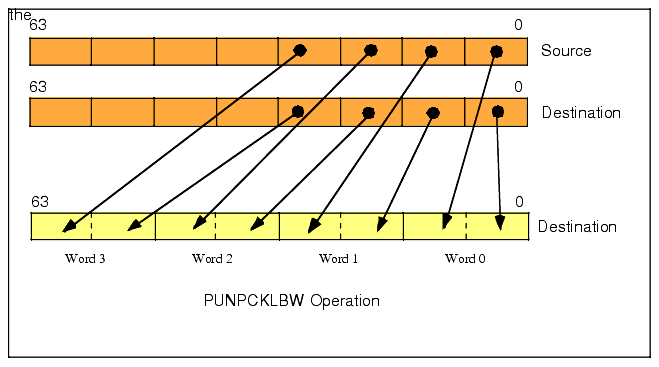
Figure 11.5 UNPCKLBW Instruction
The PUNPCKLWD instruction unpacks and interleaves the low-order two words of the source (first) and destination (second) operands. It places the L.O. two words of the destination operand at the even word positions in the destination and it places the L.O. words of the source operand in the odd word positions of the destination operand (see Figure 11.6).
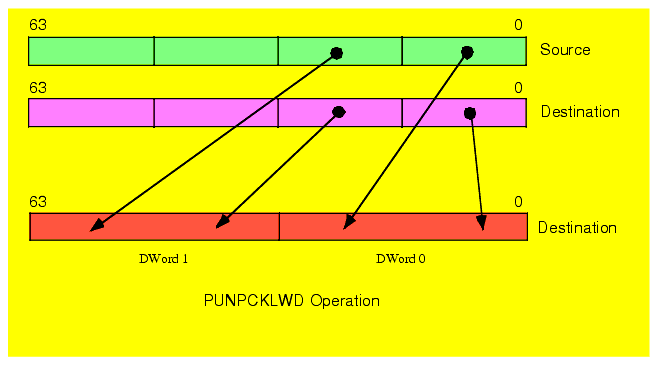
Figure 11.6 The PUNPCKLWD Instruction
The PUNPCKDQ instruction copies the L.O. dword of the source operand to the L.O. dword of the destination operand and it copies the (original) L.O. dword of the destination operand to the L.O. dword of the destination (i.e., it doesn't change the L.O. dword of the destination, see Figure 11.7).
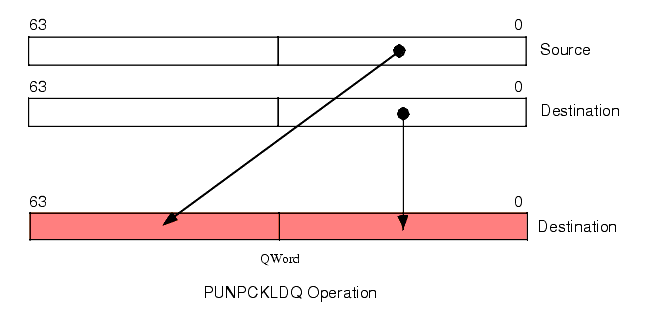
Figure 11.7 PUNPCKLDQ Instruction
The PUNPCKHBW instruction is quite similar to the PUNPCKLBW instruction. The difference is that it unpacks and interleaves the high-order four bytes of the source (first) and destination (second) operands. It places the H.O. four bytes of the destination operand at the even byte positions in the destination and it places the H.O. four bytes of the source operand in the odd byte positions of the destination operand (see Figure 11.8).
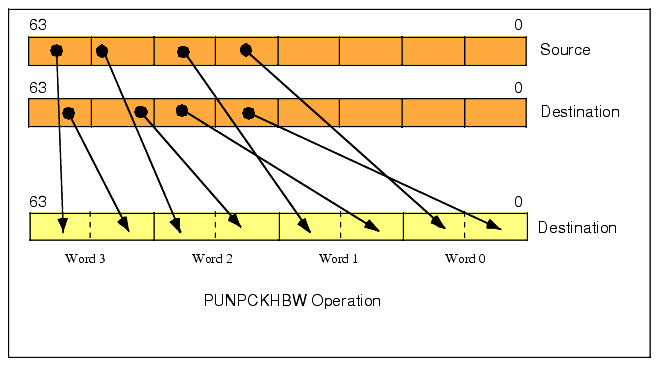
Figure 11.8 PUNPCKHBW Instruction
The PUNPCKHWD instruction unpacks and interleaves the low-order two words of the source (first) and destination (second) operands. It places the L.O. two words of the destination operand at the even word positions in the destination and it places the L.O. words of the source operand in the odd word positions of the destination operand (see Figure 11.9)
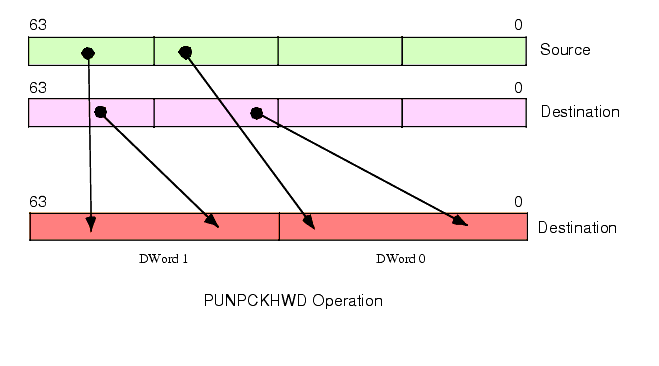
Figure 11.9 PUNPCKHWD Instruction
The PUNPCKHDQ instruction copies the H.O. dword of the source operand to the H.O. dword of the destination operand and it copies the (original) H.O. dword of the destination operand to the L.O. dword of the destination (see Figure 11.10).
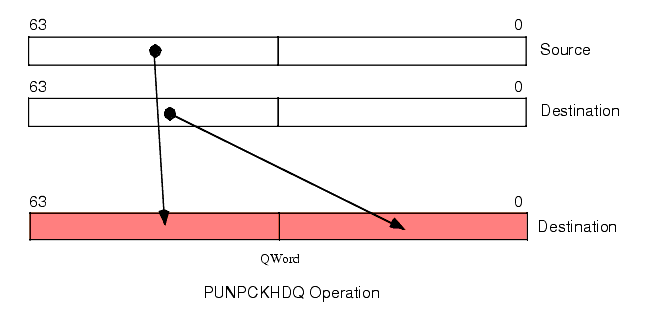
Figure 11.10 PUNPCKDQ Instruction
Since the unpack instructions provide the converse operation of the pack instructions, it should come as no surprise that you can use these instructions to perform the inverse algorithms of the examples given earlier for the pack instructions. For example, if you have a string of eight-bit ANSI characters, you can convert them to their UNICODE equivalents by setting one MMX register (the source) to all zeros. You can convert each four characters of the ANSI string to UNICODE by loading those four characters into the L.O. double word of an MMX register and executing the PUNPCKLBW instruction. This will interleave each of the characters with a zero byte, thus converting them from ANSI to UNICODE.
Of course, the unpack instructions are quite valuable any time you need to interleave data. For example, if you have three separate images containing the blue, red, and green components of a 24-bit image, it is possible to merge these three bytes together using the PUNPCKLBW instruction1.
11.7.3 MMX Packed Arithmetic Instructions
paddb( mem64, mmi ); paddb( mmi, mmi ); paddw( mem64, mmi ); paddw( mmi, mmi ); paddd( mem64, mmi ); paddd( mmi, mmi ); paddsb( mem64, mmi ); paddsb( mmi, mmi ); paddsw( mem64, mmi ); paddsw( mmi, mmi ); paddusb( mem64, mmi ); paddusb( mmi, mmi ); paddusw( mem64, mmi ); paddusw( mmi, mmi ); psubb( mem64, mmi ); psubb( mmi, mmi ); psubw( mem64, mmi ); psubw( mmi, mmi ); psubd( mem64, mmi ); psubd( mmi, mmi ); psubsb( mem64, mmi ); psubsb( mmi, mmi ); psubsw( mem64, mmi ); psubsw( mmi, mmi ); psubusb( mem64, mmi ); psubusb( mmi, mmi ); psubusw( mem64, mmi ); psubusw( mmi, mmi ); pmulhuw( mem64, mmi ); pmulhuw( mmi, mmi ); pmulhw( mem64, mmi ); pmulhw( mmi, mmi ); pmullw( mem64, mmi ); pmullw( mmi, mmi ); pmaddwd( mem64, mmi ); pmaddwd( mmi, mmi );The packed arithmetic instructions operate on a set of bytes, words, or double words within a 64-bit block. For example, the PADDW instruction computes four 16-bit sums of two operand simultaneously. None of these instructions affect the CPU's FLAGs register. Therefore, there is no indication of overflow, underflow, zero result, negative result, etc. If you need to test a result after a packed arithmetic computation, you will need to use one of the packed compare instructions (see "MMX Comparison Instructions" on page 1134).
The PADDB, PADDW, and PADDD instructions add the individual bytes, words, or double words in the two 64-bit operands using a wrap-around (i.e., non-saturating) addition. Any carry out of a sum is lost; it is your responsibility to ensure that overflow never occurs. As for the integer instructions, these packed add instructions add the values in the source operand to the destination operand, leaving the sum in the destination operand. These instructions produce correct results for signed or unsigned operands (assuming overflow/underflow does not occur).
The PADDSB and PADDSW instructions add the eight eight-bit or four 16-bit operands in the source and destination locations together using signed saturation arithmetic. The PADDUSB and PADDUSW instructions add their eight eight-bit or four 16-bit operands together using unsigned saturation arithmetic. Notice that you must use different instructions for signed and unsigned value since saturation arithmetic is different depending upon whether you are manipulating signed or unsigned operands. Also note that the instruction set does not support the saturated addition of double word values.
The PSUBB, PSUBW, and PSUBD instructions work just like their addition counterparts, except of course, they compute the wrap-around difference rather than the sum. These instructions compute dest=dest-src. Likewise, the PSUBSB, PSUBSW, PSUBUSB, and PSUBUSW instruction compute the difference of the destination and source operands using saturation arithmetic.
While addition and subtraction can produce a one-bit carry or borrow, multiplication of two n-bit operands can produce as large as a 2*n bit result. Since overflow is far more likely in multiplication than in addition or subtraction, the MMX packed multiply instructions work a little differently than their addition and subtraction counterparts. To successfully multiply two packed values requires two instructions - one to compute the L.O. component of the result and one to produce the H.O. component of the result. The PMULLW, PMULHW, and PMULHUW instructions handle this task.
The PMULLW instruction multiplies the four words of the source operand by the four words of the destination operand and stores the four L.O. words of the four double word results into the destination operand. This instruction ignores the H.O. words of the results. Used by itself, this instruction computes the wrap-around product of an unsigned or signed set of operands; this is also the L.O. words of the four products.
The PMULHW and PMULHUW instructions complete the calculation. After computing the L.O. words of the four products with the PMULLW instruction, you use either the PMULHW or PMULHUW instruction to compute the H.O. words of the products. These two instruction multiply the four words in the source by the four words in the destination and then store the H.O. words of the results in the destination MMX register. The difference between the two is that you use PMULHW for signed operands and PMULHUW for unsigned operands. If you compute the full product by using a PMULLW and a PMULHW (or PMULHUW) instruction pair, then there is no overflow possible, hence you don't have to worry about wrap-around or saturation arithmetic.
The PMADDWD instruction multiplies the four words in the source operand by the four words in the destination operand to produce four double word products. Then it adds the two L.O. double words together and stores the result in the L.O. double word of the destination MMX register; it also adds together the two H.O. double words and stores their sum in the H.O. word of the destination MMX register.
11.7.4 MMX Logic Instructions
pand( mem64, mmi ); pand( mmi, mmi ); pandn( mem64, mmi ); pandn( mmi, mmi ); por( mem64, mmi ); por( mmi, mmi ); pxor( mem64, mmi ); pxor( mmi, mmi );The packed logic instructions are some examples of MMX instructions that actually operate on 64-bit values. There are no packed byte, packed word, or packed double word versions of these instructions. Of course, there is no need for special byte, word, or double word versions of these instructions since they would all be equivalent to the 64-bit logic instruction. Hence, if you want to logically AND eight bytes together in parallel, you use the PAND instruction; likewise, if you want to logically AND four words or two double words together, you just use the PAND instruction.
The PAND, POR, and PXOR instructions do the same thing as their 32-bit integer instruction counterparts (AND, OR, XOR) except, of course, they operate on two 64-bit MMX operands. Hence, no further discussion of these instructions is really necessary here. The PANDN (AND NOT) instruction is a new logic instruction, so it bears a little bit of a discussion. The PANDN instruction computes the following result:
dest := dest and (not source);As you may recall from the chapter on Introduction to Digital Design, this is the inhibition function. If the destination operand is B and the source operand is A, this function computes B = BA'. (see "Boolean Functions and Truth Tables" on page 205 for details of the inhibition function). If you're wondering why Intel chose to include such a weird function in the MMX instruction set, well, this instruction has one very useful property: it forces bits to zero in the destination operand everywhere there is a one bit in the source operand. This is an extremely useful function for merging to 64-bit quantities together. The following code sequence demonstrates this:
readonly AlternateNibbles: qword; nostorage; qword16( $F0F0_F0F0_F0F0_F0F0 ); // Note: needs qword16 macro! . . . // Create a 64-bit value in MM0 containing the Odd nibbles from MM1 and // the even nibbles from MM0: pandn( AlternateNibbles, mm0 ); // Clear the odd numbered nibbles. pand( AlternateNibbles, mm1 ); // Clear the even numbered nibbles. por( mm1, mm0 ); // Merge the two.The PANDN operation is also useful for compute the set difference of two character sets. You could implement the cs.difference function using only six MMX instructions:
// Compute csdest := csdest - cssrc; movq( (type qword csdest), mm0 ); pandn( (type qword cssrc), mm0 ); movq( mm0, (type qword csdest )); movq( (type qword csdest[8]), mm0 ); pandn( (type qword cssrc[8]), mm0 ); movq( mm0, (type qword csdest[8] ));Of course, if you want to improve the performance of the HLA Standard Library character set functions, you can use the MMX logic instructions throughout that module. Examples of such code appear later in this chapter.
11.7.5 MMX Comparison Instructions
pcmpeqb( mem64, mmi ); pcmpeqb( mmi, mmi ); pcmpeqw( mem64, mmi ); pcmpeqw( mmi, mmi ); pcmpeqd( mem64, mmi ); pcmpeqd( mmi, mmi ); pcmpgtb( mem64, mmi ); pcmpgtb( mmi, mmi ); pcmpgtw( mem64, mmi ); pcmpgtw( mmi, mmi ); pcmpgtd( mem64, mmi ); pcmpgtd( mmi, mmi );The packed comparison instructions compare the destination (second) operand to the source (first) operand to test for equality or greater than. These instructions compare eight pairs of bytes (PCMPEQB, PCMPGTB), four pairs of words (PCMPEQW, PCMPGTW), or two pairs of double words (PCMPEQD, PCMPGTD).
The first big difference to notice about these packed comparison instructions is that they compare the second operand to the first operand. This is exactly opposite of the standard CMP instruction (that compares the first operand to the second operand). The reason for this will become clear in a moment; however, you do have to keep in mind when using these instructions that the operands are opposite what you would normally expect. If this ordering bothers you, you can create macros to reverse the operands; we will explore this possibility a little later in this section.
The second big difference between the packed comparisons and the standard integer comparison is that these instructions test for a specific condition (equality or greater than) rather than doing a generic comparison. This is because these instructions, like the other MMX instructions, do not affect any condition code bits in the FLAGs register. This may seem contradictory, after all the whole purpose of the CMP instruction is to set the condition code bits. However, keep in mind that these instructions simultaneously compare two, four, or eight operands; that implies that you would need two, four, or eight sets of condition code bits to hold the results of the comparisons. Since the FLAGs register maintains only one set of condition code bits, it is not possible to reflect the comparison status in the FLAGs. This is why the packed comparison instructions test a specific condition - so they can return true or false to indicate the result of their comparison.
Okay, so where do these instructions return their true or false values? In the destination operand, of course. This is the third big difference between the packed comparisons and the standard integer CMP instruction - the packed comparisons modify their destination operand. Specifically, the PCMPEQB and PCMPGTB instruction compare each pair of bytes in the two operands and write false ($00) or true ($FF) to the corresponding byte in the destination operand, depending on the result of the comparison. For example, the instruction "pcmpgtb( MM1, MM0 );" compares the L.O. byte of MM0 (A) with the L.O. byte of MM1 (B) and writes $00 to the L.O. byte of MM0 if A is not greater than B. It writes $FF to the L.O. byte of MM0 if A is greater than B (see Figure 11.11).
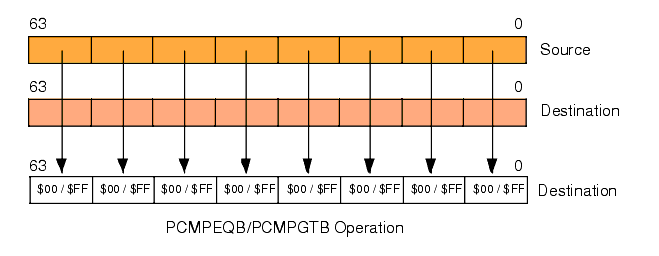
Figure 11.11 PCMPEQB and PCMPGTB Instructions
The PCMPEQW, PCMPGTW, PCMPEQD, and PCMPGTD instructions work in an analogous fashion except, of course, they compare words and double words rather than bytes (see Figure 11.12 and Figure 11.13).
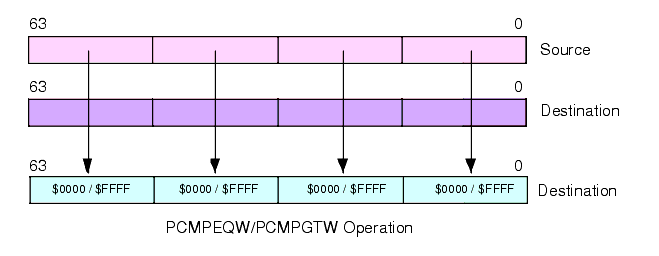
Figure 11.12 PCMPEQW and PCMPGTW Instructions
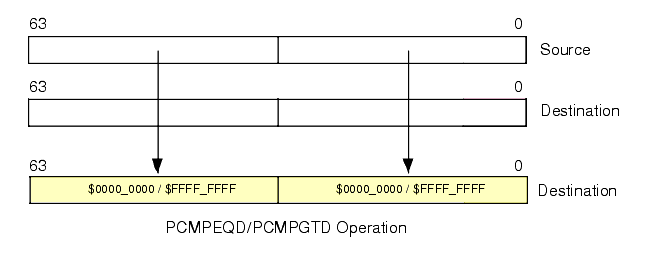
Figure 11.13 PCMPEQD and PCMPGTD Instructions
You've probably already noticed that there isn't a set of PCMPLTx instructions. Intel chose not to provide these instructions because you can simulate them with the PCMPGTx instructions by reversing the operands. That is, A>B implies B<A. Therefore, if you want to do a concurrent comparison of multiple operands for less than, you can use the PCMPGTx instructions to do this by simply reversing the operands. The only time this isn't directly possible is if your source operand is a memory operand; since the destination operand of the packed comparison instructions has to be an MMX register, you would have to move the memory operand into an MMX register before comparing them.
In addition to the lack of a packed less than comparison, you're also missing the not equals, less than or equal, and greater than or equal comparisons. You can easily synthesize these comparisons by executing a PXOR or POR instruction after the packed comparison.
To simulate a PCMPNEx instruction, all you've got to do is invert all the bits in the destination operand after executing a PCMPEQx instruction, e.g.,
pcmpeqb( mm1, mm0 ); pxor( AllOnes, mm0 ); // Assumption: AllOnes is a qword variable // containing $FFFF_FFFF_FFFF_FFFF.Of course, you can save the PXOR instruction by testing for zeros in the destination operand rather than ones (that is, use your program's logic to invert the result rather than actually computing the inverse).
To simulate the PCMPGEx and PCMPLEx instructions, you must do two comparisons, one for equality and one for greater than or less than, and then logically OR the results. Here's an example that computes MM0 <= MM1:
movq( mm1, mm2 ); // Need a copy of destination operand. pcmpgtb( mm0, mm1 ); // Remember: A<B is equal to B>A, so we're pcmpeqb( mm0, mm2 ); // MM0<MM1 and MM0=MM1 here. por( mm2, mm1 ); // Leaves boolean results in MM1.If it really bothers you to have to reverse the operands, you can create macros to create your own PCMPLTx instructions. The following example demonstrates how to create the PCMPLTB macro:
#macro pcmpltb( mmOp1, mmOp2 ); pcmpgtb( mmOp2, mmOp1 ); #endmacroOf course, you must keep in mind that there are two very big differences between this PCMPLTB "instruction" and a true PCMPLTB instruction. First, this form leaves the result in the first operand, not the second operand, hence the semantics of this "instruction" are different than the other packed comparisons. Second, the first operand has to be an MMX register while the second operand can be an MMX register or a quad word variable; again, just the opposite of the other packed instructions. The fact that this instruction's operands behave differently than the PCMPGTB instruction may create some problems. So you will have to carefully consider whether you really want to use this scheme to create a PCMPLTB "instruction" for use in your programs. If you decide to do this, it would help tremendously if you always commented each invocation of the macro to point out that the first operand is the destination operand, e.g.,
pcmpltb( mm0, mm1 ); // Computes mm0 := mm1<mm0!If the fact that the packed comparison instruction's operands are reversed bothers you, you can also use macros to swap those operands. The following example demonstrates how to write such macros for the PEQB (PCMPEQB), PGTB (PCMPGTB), and PLTB (packed less than, byte) instructions.
#macro peqb( leftOp, rightOp ); pcmpeqb( rightOp, leftOp ); #endmacro #macro pgtb( leftOp, rightOp ); pcmpgtb( rightOp, leftOp ); #endmacro #macro pltb( leftOp, rightOp ); pcmpgtb( leftOp, rightOp ); #endmacroNote that these macros don't solve the PLTB problem of having the wrong operand as the destination. However, these macros do compare the first operand to the second operand, just like the standard CMP instruction.
Of course, once you obtain a boolean result in an MMX register, you'll probably want to test the results at one point or another. Unfortunately, the MMX instructions only provide a couple of ways to move comparison information in and out of the MMX processor - you can store an MMX register value into memory or you can copy 32-bits of an MMX register to a general-purpose integer register. Since the comparison instructions produce a 64-bit result, writing the destination of a comparison to memory is the easiest way to gain access to the comparison results in your program. Typically, you'd use an instruction sequence like the following:
pcmpeqb( mm1, mm0 ); // Compare 8 bytes in mm1 to mm0. movq( mm0, qwordVar ); // Write comparison results to memory. if((type boolean qwordVar )) then << do this if byte #0 contained true ($FF, which is non-zero). >> endif; if((type boolean qwordVar[1])) then << do this if byte #1 contained true. >> endif; etc.11.7.6 MMX Shift Instructions
psllw( mmi, mmi ); psllw( imm8, mmi ); pslld( mmi, mmi ); pslld( imm8, mmi ); psllq( mmi, mmi ); psllq( imm8, mmi ); pslrw( mmi, mmi ); pslrw( imm8, mmi ); psrld( mmi, mmi ); psrld( imm8, mmi ); pslrq( mmi, mmi ); pslrq( imm8, mmi ); psraw( mmi, mmi ); psraw( imm8, mmi ); psrad( mmi, mmi ); psrad( imm8, mmi );The MMX shift, like the arithmetic instructions, allow you to simultaneously shift several different values in parallel. The PSLLx instructions perform a packed shift left logical operation, the PSLRx instructions do a packed logical shift right operation, and the PSRAx instruction do a packed arithmetic shift right operation. These instructions operate on word, double word, and quad word operands. Note that Intel does not provide a version of these instructions that operate on bytes.
The first operand to these instructions specifies a shift count. This should be an unsigned integer value in the range 0..15 for word shifts, 0..31 for double word operands, and 0..63 for quadword operands. If the shift count is outside these ranges, then these instructions set their destination operands to all zeros. If the count (first) operand is not an immediate constant, then it must be an MMX register.
The PSLLW instruction simultaneously shifts the four words in the destination MMX register to the left the number of bit positions specified by the source operand. The instruction shifts zero into the L.O. bit of each word and the bit shifted out of the H.O. bit of each word is lost. There is no carry from one word to the other (since that would imply a larger shift operation). This instruction, like all the other MMX instructions, does not affect the FLAGs register (including the carry flag).
The PSLLD instruction simultaneously shifts the two double words in the destination MMX register to the left one bit position. Like the PSLLW instruction, this instruction shifts zeros into the L.O. bits and any bits shifted out of the H.O. positions are lost.
The PSLLQ is one of the few MMX instructions that operates on 64-bit quantities. This instruction shifts the entire 64-bit destination register to the left the number of bits specified by the count (source) operand. In addition to allowing you to manipulate 64-bit integer quantities, this instruction is especially useful for moving data around in MMX registers so you can pack or unpack data as needed.
Although there is no PSLLB instruction to shift bits, you can simulate this instruction using a PSLLW and a PANDN instruction. After shifting the word values to the left the specified number of bits, all you've got to do is clear the L.O. n bits of each byte, where n is the shift count. For example, to shift the bytes in MM0 to the left three positions you could use the following two instructions:
static ThreeBitsZero: byte; @nostorage; byte $F8, $F8, $F8, $F8, $F8, $F8, $F8, $F8; . . . psllw( 3, mm0 ); pandn( ThreeBitsZero, mm0 );The PSLRW, PSLRD, and PSLRQ instructions work just like their left shift counterparts except that these instructions shift their operands to the right rather than to the left. They shift zeros into the vacated H.O. positions of the destination values and bits they shift out of the L.O. bits are lost. As with the shift left instructions, there is no PSLRB instruction but you can easily simulate this with a PSLRW and a PANDN instruction.
The PSRAW and PSRAD instructions do an arithmetic shift right operation on the words or double words in the destination MMX register. Note that there isn't a PSRAQ instruction. While shifting data to the right, these instructions replicate the H.O. bit of each word, double word, or quad word rather than shifting in zeros. As for the logical shift right instructions, bits that these instructions shift out of the L.O. bits are lost forever.
The PSLLQ and PSLRQ instructions provide a convenient way to shift a quad word to the left or right. However, the MMX shift instructions are not generally useful for extended precision shifts since all data shifted out of the operands is lost. If you need to do an extended precision shift other than 64 bits, you should stick with the SHLD and SHRD instructions. The MMX shift instructions are mainly useful for shifting several values in parallel or (PSLLQ and PSLRQ) repositioning data in an MMX register.
11.8 The EMMS Instruction
emms();The EMMS (Empty MMX Machine State) instruction restores the FPU status on the CPU so that it can begin processing FPU instructions again after an MMX instruction sequence. You should always execute the EMMS instruction once you complete some MMX sequence. Failure to do so may cause any following floating point instructions to fail.
When an MMX instruction executes, the floating point tag word is marked valid (00s). Subsequent floating-point instructions that will be executed may produce unexpected results because the floating-point stack seems to contain valid data. The EMMS instruction marks the floating point tag word as empty. This must occur before the execution of any following floating point instructions.
Of course, you don't have to execute the EMMS instruction immediately after an MMX sequence if you're going to execute some additional MMX instructions prior to executing any FPU instructions, but you must take care to execute this instruction if
- You call any library routines or OS APIs (that might possibly use the FPU).
- You switch tasks in a cooperative fashion (for example, see the chapter on Coroutines in the Volume on Advanced Procedures).
- You execute any FPU instructions.
If the EMMS instruction is not used when trying to execute a floating-point instruction, the following may occur:
- Depending on the exception mask bits of the floating-point control word, a floating point exception event may be generated.
- A "soft exception" may occur. In this case floating-point code continues to execute, but generates incorrect results.
The EMMS instruction is rather slow, so you don't want to unnecessarily execute it, but it is critical that you execute it at the appropriate times. Of course, better safe that sorry; if you're not sure you're going to execute more MMX instructions before any FPU instructions, then go ahead and execute the EMMS instruction to clear the state.
1Typically you would merge in a fourth byte of zero and then store the resulting double word every three bytes in memory to overwrite the zeros.
|