
3.8 Parameters
Although there is a large class of procedures that are totally self-contained, most procedures require some input data and return some data to the caller. Parameters are values that you pass to and from a procedure. There are many facets to parameters. Questions concerning parameters include:
- where is the data coming from?
- what mechanism do you use to pass and return data?
- how much data are you passing?
In this chapter we will take another look at the two most common parameter passing mechanisms: pass by value and pass by reference. We will also discuss three popular places to pass parameters: in the registers, on the stack, and in the code stream. The amount of parameter data has a direct bearing on where and how to pass it. The following sections take up these issues.
3.8.1 Pass by Value
A parameter passed by value is just that - the caller passes a value to the procedure. Pass by value parameters are input only parameters. That is, you can pass them to a procedure but the procedure cannot return values through them. In high level languages the idea of a pass by value parameter being an input only parameter makes a lot of sense. Given the procedure call:
CallProc(I);If you pass I by value, CallProc does not change the value of I, regardless of what happens to the parameter inside CallProc.
Since you must pass a copy of the data to the procedure, you should only use this method for passing small objects like bytes, words, and double words. Passing arrays and strings by value is very inefficient (since you must create and pass a copy of the structure to the procedure).
3.8.2 Pass by Reference
To pass a parameter by reference you must pass the address of a variable rather than its value. In other words, you must pass a pointer to the data. The procedure must dereference this pointer to access the data. Passing parameters by reference is useful when you must modify the actual parameter or when you pass large data structures between procedures.
Passing parameters by reference can produce some peculiar results. The following Pascal procedure provides an example of one problem you might encounter:
program main(input,output); var m:integer;(* ** Note: this procedure passes i and j by reference. *)procedure bletch(var i,j:integer); begini := i+2; j := j-i; writeln(i,' `,j);end;. . .begin {main}m := 5; bletch(m,m);end.This particular code sequence will print "00" regardless of m's value. This is because the parameters i and j are pointers to the actual data and they both point at the same object (that is, they are aliases). Therefore, the statement "j:=j-i;" always produces zero since i and j refer to the same variable.
Pass by reference is usually less efficient than pass by value. You must dereference all pass by reference parameters on each access; this is slower than simply using a value. However, when passing a large data structure, pass by reference is faster because you do not have to copy a large data structure before calling the procedure.
3.8.3 Passing Parameters in Registers
Having touched on how to pass parameters to a procedure, the next thing to discuss is where to pass parameters. Where you pass parameters depends on the size and number of those parameters. If you are passing a small number of bytes to a procedure, then the registers are an excellent place to pass parameters to a procedure. If you are passing a single parameter to a procedure you should use the following registers for the accompanying data types:
Data Size Pass in this Register
This is not a hard and fast rule. If you find it more convenient to pass 16 bit values in the SI or BX register, do so. However, most programmers use the registers above to pass parameters.
If you are passing several parameters to a procedure in the 80x86's registers, you should probably use up the registers in the following order:
In general, you should avoid using EBP register. If you need more than six double words, perhaps you should pass your values elsewhere.
As an example, consider the following "strfill(str,c);" that copies the character c (passed by value in AL) to each character position in s (passed by reference in EDI) up to a zero terminating byte:
// strfill- Overwrites the data in a string with a character. // // EDI- pointer to zero terminated string (e.g., an HLA string) // AL- character to store into the string. procedure strfill; nodisplay; begin strfill; push( edi ); // Preserve this because it will be modified. while( (type char [edi] <> #0 ) do mov( al, [edi] ); inc( edi ); endwhile; pop( edi ); end strfill;To call the strfill procedure you would load the address of the string data into EDI and the character value into AL prior to the call. The following code fragment demonstrates a typical call to strfill:
mov( s, edi ); // Get ptr to string data into edi (assumes s:string). mov( ` `, al ); strfill();Don't forget that HLA string variables are pointers. This example assumes that s is a HLA string variable and, therefore, contains a pointer to a zero-terminated string. Therefore, the "mov( s, edi );" instruction loads the address of the zero terminated string into the EDI register (hence this code passes the address of the string data to strfill, that is, it passes the string by reference).
One way to pass parameters in the registers is to simply load the registers with the appropriate values prior to a call and then reference the values in those registers within the procedure. This is the traditional mechanism for passing parameters in registers in an assembly language program. HLA, being somewhat more high level than traditional assembly language, provides a formal parameter declaration syntax that lets you tell HLA you're passing certain parameters in the general purpose registers. This declaration syntax is the following:
parmName: parmType in regWhere parmName is the parameter's name, parmType is the type of the object, and reg is one of the 80x86's general purpose eight, sixteen, or thirty-two bit registers. The size of the parameter's type must be equal to the size of the register or HLA will generate an error. Here is a concrete example:
procedure HasRegParms( count: uns32 in ecx; charVal:char in al );One nice feature to this syntax is that you can call a procedure that has register parameters exactly like any other procedure in HLA using the high level syntax, e.g.,
HasRegParms( ecx, bl );If you specify the same register as an actual parameter that you've declared for the formal parameter, HLA does not emit any extra code; it assumes that the parameter is already in the appropriate register. For example, in the call above the first actual parameter is the value in ECX; since the procedure's declaration specifies that that first parameter is in ECX HLA will not emit any code. On the other hand, the second actual parameter is in BL while the procedure will expect this parameter value in AL. Therefore, HLA will emit a "mov( bl, al );" instruction prior to calling the procedure so that the value is in the proper register upon entry to the procedure.
You can also pass parameters by reference in a register. Consider the following declaration:
procedure HasRefRegParm( var myPtr:uns32 in edi );A call to this procedure always requires some memory operand as the actual parameter. HLA will emit the code to load the address of that memory object into the parameter's register (EDI in this case). Note that when passing reference parameters, the register must be a 32-bit general purpose register since addresses are 32-bits long. Here's an example of a call to HasRefRegParm:
HasRefRegParm( x );HLA will emit either a "mov( &x, edi);" or "lea( edi, x);" instruction to load the address of x into the EDI registers prior to the CALL instruction1.
If you pass an anonymous memory object (e.g., "[edi]" or "[ecx]") as a parameter to HasRefRegParm, HLA will not emit any code if the memory reference uses the same register that you declare for the parameter (i.e., "[edi]"). It will use a simple MOV instruction to copy the actual address into EDI if you specify an indirect addressing mode using a register other than EDI (e.g., "[ecx]"). It will use an LEA instruction to compute the effective address of the anonymous memory operand if you use a more complex addressing mode like "[edi+ecx*4+2]".
Within the procedure's code, HLA creates text equates for these register parameters that map their names to the appropriate register. In the HasRegParms example, any time you reference the count parameter, HLA substitutes "ecx" for count. Likewise, HLA substitutes "al" for charVal throughout the procedure's body. Since these names are aliases for the registers, you should take care to always remember that you cannot use ECX and AL independently of these parameters. It would be a good idea to place a comment next to each use of these parameters to remind the reader that count is equivalent to ECX and charVal is equivalent to AL.
3.8.4 Passing Parameters in the Code Stream
Another place where you can pass parameters is in the code stream immediately after the CALL instruction. Consider the following print routine that prints a literal string constant to the standard output device:
call print; byte "This parameter is in the code stream.",0;Normally, a subroutine returns control to the first instruction immediately following the CALL instruction. Were that to happen here, the 80x86 would attempt to interpret the ASCII codes for "This..." as an instruction. This would produce undesirable results. Fortunately, you can skip over this string when returning from the subroutine.
So how do you gain access to these parameters? Easy. The return address on the stack points at them. Consider the following implementation of print:
program printDemo; #include( "stdlib.hhf" ); // print- // // This procedure writes the literal string // immediately following the call to the // standard output device. The literal string // must be a sequence of characters ending with // a zero byte (i.e., a C string, not an HLA // string). procedure print; @noframe; @nodisplay; const // RtnAdrs is the offset of this procedure's // return address in the activation record. RtnAdrs:text := "(type dword [ebp+4])"; begin print; // Build the activation record (note the // "@noframe" option above). push( ebp ); mov( esp, ebp ); // Preserve the registers this function uses. push( eax ); push( ebx ); // Copy the return address into the EBX // register. Since the return address points // at the start of the string to print, this // instruction loads EBX with the address of // the string to print. mov( RtnAdrs, ebx ); // Until we encounter a zero byte, print the // characters in the string. forever mov( [ebx], al ); // Get the next character. breakif( !al ); // Quit if it's zero. stdout.putc( al ); // Print it. inc( ebx ); // Move on to the next char. endfor; // Skip past the zero byte and store the resulting // address over the top of the return address so // we'll return to the location that is one byte // beyond the zero terminating byte of the string. inc( ebx ); mov( ebx, RtnAdrs ); // Restore EAX and EBX. pop( ebx ); pop( eax ); // Clean up the activation record and return. pop( ebp ); ret(); end print; begin printDemo; // Simple test of the print procedure. call print; byte "Hello World!", 13, 10, 0 ; end printDemo; Program 3.3 Print Procedure Implementation (Using Code Stream Parameters)Besides showing how to pass parameters in the code stream, the print routine also exhibits another concept: variable length parameters. The string following the CALL can be any practical length. The zero terminating byte marks the end of the parameter list. There are two easy ways to handle variable length parameters. Either use some special terminating value (like zero) or you can pass a special length value that tells the subroutine how many parameters you are passing. Both methods have their advantages and disadvantages. Using a special value to terminate a parameter list requires that you choose a value that never appears in the list. For example, print uses zero as the terminating value, so it cannot print the NUL character (whose ASCII code is zero). Sometimes this isn't a limitation. Specifying a special length parameter is another mechanism you can use to pass a variable length parameter list. While this doesn't require any special codes or limit the range of possible values that can be passed to a subroutine, setting up the length parameter and maintaining the resulting code can be a real nightmare2.
Despite the convenience afforded by passing parameters in the code stream, there are some disadvantages to passing parameters there. First, if you fail to provide the exact number of parameters the procedure requires, the subroutine will get very confused. Consider the print example. It prints a string of characters up to a zero terminating byte and then returns control to the first instruction following the zero terminating byte. If you leave off the zero terminating byte, the print routine happily prints the following opcode bytes as ASCII characters until it finds a zero byte. Since zero bytes often appear in the middle of an instruction, the print routine might return control into the middle of some other instruction. This will probably crash the machine. Inserting an extra zero, which occurs more often than you might think, is another problem programmers have with the print routine. In such a case, the print routine would return upon encountering the first zero byte and attempt to execute the following ASCII characters as machine code. Once again, this usually crashes the machine. These are the some of the reasons why the HLA stdout.put code does not pass its parameters in the code stream. Problems notwithstanding, however, the code stream is an efficient place to pass parameters whose values do not change.
3.8.5 Passing Parameters on the Stack
Most high level languages use the stack to pass parameters because this method is fairly efficient. By default, HLA also passes parameters on the stack. Although passing parameters on the stack is slightly less efficient than passing those parameters in registers, the register set is very limited and you can only pass a few value or reference parameters through registers. The stack, on the other hand, allows you to pass a large amount of parameter data without any difficulty. This is the principal reason that most programs pass their parameters on the stack.
HLA passes parameters you specify in a high-level language form on the stack. For example, suppose you define strfill from the previous section as follows:
procedure strfill( s:string; chr:char );Calls of the form "strfill( s, ` ` );" will pass the value of s (which is an address) and a space character on the 80x86 stack. When you specify a call to strfill in this manner, HLA automatically pushes the parameters for you, so you don't have to push them onto the stack yourself. Of course, if you choose to do so, HLA will let you manually push the parameters onto the stack prior to the call.
To manually pass parameters on the stack, push them immediately before calling the subroutine. The subroutine then reads this data from the stack memory and operates on it appropriately. Consider the following HLA procedure call:
CallProc(i,j,k);HLA pushes parameters onto the stack in the order that they appear in the parameter list3. Therefore, the 80x86 code HLA emits for this subroutine call (assuming you're passing the parameters by value) is
push( i ); push( j ); push( k ); call CallProc;Upon entry into CallProc, the 80x86's stack looks like that shown in Figure 3.7:
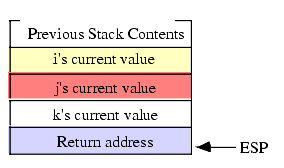
Figure 3.7 Stack Layout Upon Entry into CallProc
You could gain access to the parameters passed on the stack by removing the data from the stack as the following code fragment demonstrates:
// Note: to extract parameters off the stack by popping it is very important // to specify both the @nodisplay and @noframe procedure options. static RtnAdrs: dword; p1Parm: dword; p2Parm: dword; p3Parm: dword; procedure CallProc( p1:dword; p2:dword; p3:dword ); @nodisplay; @noframe; begin CallProc; pop( RtnAdrs ); pop( p3Parm ); pop( p2Parm ); pop( p1Parm ); push( RtnAdrs ); . . . ret(); end CallProc;As you can see from this code, it first pops the return address off the stack and into the RtnAdrs variable; then it pops (in reverse order) the values of the p1, p2, and p3 parameters; finally, it pushes the return address back onto the stack (so the RET instruction will operate properly). Within the CallProc procedure, you may access the p1Parm, p2Parm, and p3Parm variables to use the p1, p2, and p3 parameter values.
There is, however, a better way to access procedure parameters. If your procedure includes the standard entry and exit sequences (see "The Standard Entry Sequence" on page 813 and "The Standard Exit Sequence" on page 814), then you may directly access the parameter values in the activation record by indexing off the EBP register. Consider the layout of the activation record for CallProc that uses the following declaration:
procedure CallProc( p1:dword; p2:dword; p3:dword ); @nodisplay; @noframe; begin CallProc; push( ebp ); // This is the standard entry sequence. mov( esp, ebp ); // Get base address of A.R. into EBP. . . .Take a look at the stack immediately after the execution of "mov( esp, ebp );" in CallProc. Assuming you've pushed three double word parameters onto the stack, it should look something like shown in Figure 3.8:
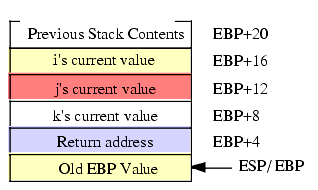
Figure 3.8 Activation Record for CallProc After Standard Entry Sequence Execution
.Now you can access the parameters by indexing off the EBP register:
mov( [ebp+16], eax ); // Accesses the first parameter. mov( [ebp+12], ebx ); // Accesses the second parameter. mov( [ebp+8], ecx ); // Accesses the third parameter.Of course, like local variables, you'd never really access the parameters in this way. You can use the formal parameter names (p1, p2, and p3) and HLA will substitute a suitable "[ebp+displacement]" memory address. Even though you shouldn't actually access parameters using address expressions like "[ebp+12]" it's important to understand their relationship to the parameters in your procedures.
Other items that often appear in the activation record are register values your procedure preserves. The most rational place to preserve registers in a procedure is in the code immediately following the standard entry sequence. In a standard HLA procedure (one where you do not specify the NOFRAME option), this simply means that the code that preserves the registers should appear first in the procedure's body. Likewise, the code to restore those register values should appear immediately before the END clause for the procedure4.
3.8.5.1 Accessing Value Parameters on the Stack
Accessing parameters passed by value is no different than accessing a local VAR object. As long as you've declared the parameter in a formal parameter list and the procedure executes the standard entry sequence upon entry into the program, all you need do is specify the parameter's name to reference the value of that parameter. The following is an example program whose procedure accesses a parameter the main program passes to it by value:
program AccessingValueParameters; #include( "stdlib.hhf" ) procedure ValueParm( theParameter: uns32 ); @nodisplay; begin ValueParm; mov( theParameter, eax ); add( 2, eax ); stdout.put ( "theParameter + 2 = ", (type uns32 eax), nl ); end ValueParm; begin AccessingValueParameters; ValueParm( 10 ); ValueParm( 135 ); end AccessingValueParameters; Program 3.4 Demonstration of Value ParametersAlthough you may access the value of theParameter using the anonymous address "[EBP+8]" within your code, there is absolutely no good reason for doing so. If you declare the parameter list using the HLA high level language syntax, you can access the value parameter by specifying its name within the procedure.
3.8.5.2 Passing Value Parameters on the Stack
As Program 3.4 demonstrates, passing a value parameter to a procedure is very easy. Just specify the value in the actual parameter list as you would for a high level language call. Actually, the situation is a little more complicated than this. Passing value parameters is easy if you're passing constant, register, or variable values. It gets a little more complex if you need to pass the result of some expression. This section deals with the different ways you can pass a parameter by value to a procedure.
Of course, you do not have to use the HLA high level language syntax to pass value parameters to a procedure. You can push these values on the stack yourself. Since there are many times it is more convenient or more efficient to manually pass the parameters, describing how to do this is a good place to start.
As noted earlier in this chapter, when passing parameters on the stack you push the objects in the order they appear in the formal parameter list (from left to right). When passing parameters by value, you should push the values of the actual parameters onto the stack. The following program demonstrates how to do this:
program ManuallyPassingValueParameters; #include( "stdlib.hhf" ) procedure ThreeValueParms( p1:uns32; p2:uns32; p3:uns32 ); @nodisplay; begin ThreeValueParms; mov( p1, eax ); add( p2, eax ); add( p3, eax ); stdout.put ( "p1 + p2 + p3 = ", (type uns32 eax), nl ); end ThreeValueParms; static SecondParmValue:uns32 := 25; begin ManuallyPassingValueParameters; pushd( 10 ); // Value associated with p1. pushd( SecondParmValue); // Value associated with p2. pushd( 15 ); // Value associated with p3. call ThreeValueParms; end ManuallyPassingValueParameters; Program 3.5 Manually Passing Parameters on the StackNote that if you manually push the parameters onto the stack as this example does, you must use the CALL instruction to call the procedure. If you attempt to use a procedure invocation of the form "ThreeValueParms();" then HLA will complain about a mismatched parameter list. HLA won't realize that you've manually pushed the parameters (as far as HLA is concerned, those pushes appear to preserve some other data).
Generally, there is little reason to manually push a parameter onto the stack if the actual parameter is a constant, a register value, or a variable. HLA's high level syntax handles most such parameters for you. There are several instances, however, where HLA's high level syntax won't work. The first such example is passing the result of an arithmetic expression as a value parameter. Since arithmetic expressions don't exist in HLA, you will have to manually compute the result of the expression and pass that value yourself. There are two possible ways to do this: calculate the result of the expression and manually push that result onto the stack, or compute the result of the expression into a register and pass the register as a parameter to the procedure. Program 3.6 demonstrates these two mechanisms.
program PassingExpressions; #include( "stdlib.hhf" ) procedure ExprParm( exprValue:uns32 ); @nodisplay; begin ExprParm; stdout.put( "exprValue = ", exprValue, nl ); end ExprParm; static Operand1: uns32 := 5; Operand2: uns32 := 20; begin PassingExpressions; // ExprParm( Operand1 + Operand2 ); // // Method one: Compute the sum and manually // push the sum onto the stack. mov( Operand1, eax ); add( Operand2, eax ); push( eax ); call ExprParm; // Method two: Compute the sum in a register and // pass the register using the HLA high level // language syntax. mov( Operand1, eax ); add( Operand2, eax ); ExprParm( eax ); end PassingExpressions; Program 3.6 Passing the Result of Some Arithmetic Expression as a ParameterThe examples up to this point in this section have made an important assumption: that the parameter you are passing is a double word value. The calling sequence changes somewhat if you're passing parameters that are not four-byte objects. Because HLA can generate relatively inefficient code when passing objects that are not four-bytes long, manually passing such objects is a good idea if you want to have the fastest possible code.
HLA requires that all value parameters be an even multiple of four bytes long5. If you pass an object that is less than four bytes long, HLA requires that you pad the parameter data with extra bytes so that you always pass an object that is at least four bytes in length. For parameters that are larger than four bytes, you must ensure that you pass an even multiple of four bytes as the parameter value, adding extra bytes at the high-order end of the object to pad it, as necessary.
Consider the following procedure prototype:
procedure OneByteParm( b:byte );The activation record for this procedure looks like the following:
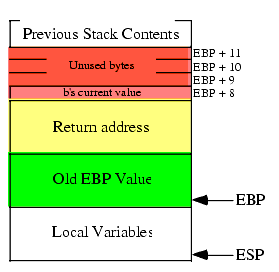
Figure 3.9 OneByteParm Activation Record
As you can see, there are four bytes on the stack associated with the b parameter, but only one of the four bytes contains valid data (the L.O. byte). The remaining three bytes are just padding and the procedure should ignore these bytes. In particular, you should never assume that these extra bytes contain zeros or some other consistent value. Depending on the type of parameter you pass, HLA's automatic code generation may or may not push zero bytes as the extra data on the stack.
When passing a byte parameter to a procedure, HLA will automatically emit code that pushes four bytes on the stack. Because HLA's parameter passing mechanism guarantees not to disturb any register or other values, HLA often generates more code than is actually needed to pass a byte parameter. For example, if you decide to pass the AL register as the byte parameter, HLA will emit code that pushes the EAX register onto the stack. This single push instruction is a very efficient way to pass AL as a four-byte parameter object. On the other hand, if you decide to pass the AH register as the byte parameter, pushing EAX won't work because this would leave the value in AH at offset EBP+9 in the activation record shown in Figure 3.9. Unfortunately, the procedure expects this value at offset EBP+8 so simply pushing EAX won't do the job. If you pass AH, BH, CH, or DH as a byte parameter, HLA emits code like the following:
sub( 4, esp ); // Make room for the parameter on the stack. mov( ah, [esp] ); // Store AH into the L.O. byte of the parameter.As you can clearly see, passing one of the "H" registers as a byte parameter is less efficient (two instructions) than passing one of the "L" registers. So you should attempt to use the "L" registers whenever possible if passing an eight-bit register as a parameter6. Note, by the way, that there is very little you can do about the difference in efficiency, even if you manually pass the parameters yourself.
If the byte parameter you decide to pass is a variable rather than a register, HLA generates decidedly worse code. For example, suppose you call OneByteParm as follows:
OneByteParm( uns8Var );For this call, HLA will emit code similar to the following to push this single byte parameter:
push( eax ); push( eax ); mov( uns8Var, al ); mov( al, [esp+4] ); pop( eax );As you can plainly see, this is a lot of code to pass a single byte on the stack! HLA emits this much code because (1) it guarantees not to disturb any registers, and (2) it doesn't know whether uns8Var is the last variable in allocated memory. You can generate much better code if you don't have to enforce either of these two constraints.
If you've got a spare 32-bit register laying around (especially one of EAX, EBX, ECX or EDX) then you can pass a byte parameter on the stack using only two instructions. Move (or move with zero/sign extension) the byte value into the register and then push the register onto the stack. For the current call to OneByteParm, the calling sequence would look like the following in EAX is available:
mov( uns8Var, al ); push( eax ); call OneByteParm;If only ESI or EDI were available, you could use code like this:
movzx( uns8Var, esi ); push( esi ); call OneByteParm;Another trick you can use to pass the parameter with only a single push instruction is to coerce the byte variable to a double word object, i.e.,
push( (type dword uns8Var)); call OneByteParm;This last example is very efficient. Note that it pushes the first three bytes of whatever value happens to follow uns8Var in memory as the padding bytes. HLA doesn't use this technique because there is a (very tiny) chance that using this scheme will cause the program to fail. If it turns out that the uns8Var object is the last byte of a given page in memory and the next page of memory is unreadable, the PUSH instruction will cause a memory access exception. To be on the safe side, the HLA compiler does not use this scheme. However, if you always ensure that the actual parameter you pass in this fashion is not the last variable you declare in a static section, then you can get away with code that uses this technique. Since it is nearly impossible for the byte object to appear at the last accessible address on the stack, it is probably safe to use this technique with VAR objects.
When passing word parameters on the stack you must also ensure that you include padding bytes so that each parameter consumes an even multiple of four bytes. You can use the same techniques we use to pass bytes except, of course, there are two valid bytes of data to pass instead of one. For example, you could use either of the following two schemes to pass a word object w to a OneWordParm procedure:
mov( w, ax ); push( eax ); call OneWordParm; push( (type dword w) ); call OneWordParm;When passing large objects by value on the stack (e.g., records and arrays), you do not have to ensure that each element or field of the object consumes an even multiple of four bytes; all you need to do is ensure that the entire data structure consumes an even multiple of four bytes on the stack. For example, if you have an array of 10 three-byte elements, the entire array will need two bytes of padding (10*3 is 30 bytes which is not evenly divisible by four, but 10*3 + 2 is 32 which is divisible by four). HLA does a fairly good job of passing large data objects by value to a procedure. For larger objects, you should use the HLA high level language procedure invocation syntax unless you have some special requirements. Of course, if you want efficient operation, you should try to avoid passing large data structures by value.
By default, HLA guarantees that it won't disturb the values of any registers when it emits code to pass parameters to a procedure. Sometimes this guarantee isn't necessary. For example, if you are returning a function result in EAX and you are not passing a parameter to a procedure in EAX, there really is no reason to preserve EAX upon entry into the procedure. Rather than generating some crazy code like the following to pass a byte parameter:
push( eax ); push( eax ); mov( uns8Var, al ); mov( al, [esp+4] ); pop( eax );HLA could generate much better code if it knows that it can use EAX (or some other register):
mov( uns8Var, al ); push( eax );You can use the @USE procedure option to tell HLA that it can modify a register's value if doing so would improve the code it generates when passing parameters. The syntax for this option is
@use genReg32;The genReg32 operand can be EAX, EBX, ECX, EDX, ESI, or EDI. You'll obtain the best results if this register is one of EAX, EBX, ECX, or EDX. Particularly, you should note that you cannot specify EBP or ESP here (since the procedure already uses those registers).
The @USE procedure option tells HLA that it's okay to modify the value of the register you specify as an operand. Therefore, if HLA can generate better code by not preserving that register's value, it will do so. For example, when the "@use eax;" option is provided for the OneByteParm procedure given earlier, HLA will only emit the two instructions immediately above rather than the five-instruction sequence that preserves EAX.
You must exercise care when specifying the @USE procedure option. In particular, you should not be passing any parameters in the same register you specify in the @USE option (since HLA may inadvertently scramble the parameter's value if you do this). Likewise, you must ensure that it's really okay for the procedure to change the register's value. As noted above, the best choice for an @USE register is EAX when the procedure is returning a function result in EAX (since, clearly, the caller will not expect the procedure to preserve EAX).
If your procedure has a FORWARD or EXTERNAL declaration, the @USE option must only appear in the FORWARD or EXTERNAL definition, not in the actual procedure declaration. If no such procedure prototype appears, then you must attach the @USE option to the procedure declaration.
procedure OneByteParm( b:byte ); @nodisplay; @use EAX; begin OneByteParm; << Do something with b >> end OneByteParm; . . . static byteVar:byte; . . . OneByteParm( byteVar );This call to OneByteParm emits the following instructions:
mov( uns8Var, al ); push( eax );3.8.5.3 Accessing Reference Parameters on the Stack
Since HLA passes the address of the actual parameters for reference parameters, accessing the reference parameters within a procedure is slightly more difficult than accessing value parameters because you have to dereference the pointers to the reference parameters. Unfortunately, HLA's high level syntax for procedure declarations and invocations does not (and cannot) abstract this detail away for you. You will have to manually dereference these pointers yourself. This section reviews how you do this.
Consider the following program:
program AccessingReferenceParameters; #include( "stdlib.hhf" ) procedure RefParm( var theParameter: uns32 ); @nodisplay; begin RefParm; // Add two directly to the parameter passed by // reference to this procedure. mov( theParameter, eax ); add( 2, (type uns32 [eax]) ); // Fetch the value of the reference parameter // and print it's value. mov( [eax], eax ); stdout.put ( "theParameter now equals ", (type uns32 eax), nl ); end RefParm; static p1: uns32 := 10; p2: uns32 := 15; begin AccessingReferenceParameters; RefParm( p1 ); RefParm( p2 ); stdout.put( "On return, p1=", p1, " and p2=", p2, nl ); end AccessingReferenceParameters; Program 3.7 Accessing a Reference ParameterIn this example the RefParm procedure has a single pass by reference parameter. Pass by reference parameters are always a pointer to the type specified by the parameter's declaration. Therefore, theParameter is actual an object of type "pointer to uns32" rather than an uns32 value. In order to access the value associated with theParameter, this code has to load that double word address into a 32-bit register and access the data indirectly. The "mov( theParameter, eax);" instruction in the code above fetches this pointer into the EAX register and then the procedure uses the "[eax]" addressing mode to access the actual value of theParameter.
Since this procedure accesses the data of the actual parameter, adding two to this data affects the values of the variables passed to the RefParm procedure from the main program. Of course, this should come as no surprise since this is the standard semantics for pass by reference parameters.
As you can see, accessing (small) pass by reference parameters is a little less efficient than accessing value parameters because you need an extra instruction to load the address into a 32-bit pointer register (not to mention, you have to reserve a 32-bit register for this purpose). If you access reference parameters frequently, these extra instructions can really begin to add up, reducing the efficiency of your program. Furthermore, it's easy to forget to dereference a reference parameter and use the address of the value instead of the value in your calculations (this is especially true when passing double-word parameters, like the uns32 parameter in the example above, to your procedures). Therefore, unless you really need to affect the value of the actual parameter, you should use pass by value to pass small objects to a procedure.
Passing large objects, like arrays and records, is where reference parameters become very efficient. When passing these objects by value, the calling code has to make a copy of the actual parameter; if the actual parameter is a large object, the copy process can be very inefficient. Since computing the address of a large object is just as efficient as computing the address of a small scalar object, there is no efficiency loss when passing large objects by reference. Within the procedure you must still dereference the pointer to access the object but the efficiency loss due to indirection is minimal when you contrast this with the cost of copying that large object. The following program demonstrates how to use pass by reference to initialize an array of records:
program accessingRefArrayParameters; #include( "stdlib.hhf" ) const NumElements := 64; type Pt: record x:uns8; y:uns8; endrecord; Pts: Pt[NumElements]; procedure RefArrayParm( var ptArray: Pts ); @nodisplay; begin RefArrayParm; push( eax ); push( ecx ); push( edx ); mov( ptArray, edx ); // Get address of parameter into EDX. for( mov( 0, ecx ); ecx < NumElements; inc( ecx )) do // For each element of the array, set the "x" field // to (ecx div 8) and set the "y" field to (ecx mod 8). mov( cl, al ); shr( 3, al ); // ECX div 8. mov( al, (type Pt [edx+ecx*2]).x ); mov( cl, al ); and( %111, al ); // ECX mod 8. mov( al, (type Pt [edx+ecx*2]).y ); endfor; pop( edx ); pop( ecx ); pop( eax ); end RefArrayParm; static MyPts: Pts; begin accessingRefArrayParameters; // Initialize the elements of the array. RefArrayParm( MyPts ); // Display the elements of the array. for( mov( 0, ebx ); ebx < NumElements; inc( ebx )) do stdout.put ( "RefArrayParm[", (type uns32 ebx):2, "].x=", MyPts.x[ ebx*2 ], " RefArrayParm[", (type uns32 ebx):2, "].y=", MyPts.y[ ebx*2 ], nl ); endfor; end accessingRefArrayParameters; Program 3.8 Passing an Array of Records by ReferencingAs you can see from this example, passing large objects by reference isn't particularly inefficient. Other than tying up the EDX register throughout the RefArrayParm procedure plus a single instruction to load EDX with the address of the reference parameter, the RefArrayParm procedure doesn't require many more instructions than the same procedure where you would pass the parameter by value.
3.8.5.4 Passing Reference Parameters on the Stack
HLA's high level syntax often makes passing reference parameters a breeze. All you need to do is specify the name of the actual parameter you wish to pass in the procedure's parameter list. HLA will automatically emit some code that will compute the address of the specified actual parameter and push this address onto the stack. However, like the code HLA emits for value parameters, the code HLA generates to pass the address of the actual parameter on the stack may not be the most efficient that is possible. Therefore, if you want to write fast code, you may want to manually write the code to pass reference parameters to a procedure. This section discusses how to do exactly that.
Whenever you pass a static object as a reference parameter, HLA generates very efficient code to pass the address of that parameter to the procedure. As an example, consider the following code fragment:
procedure HasRefParm( var d:dword ); . . . static FourBytes:dword; var v: dword; . . . HasRefParm( FourBytes ); . . .For the call to the HasRefParm procedure, HLA emits the following instruction sequence:
pushd( &FourBytes ); call HasRefParm;You really aren't going to be able to do substantially better than this if you are passing your reference parameters on the stack. So if you're passing static objects as reference parameters, HLA generates fairly good code and you should stick with the high level syntax for the procedure call.
Unfortunately, when passing automatic (VAR) objects or indexed variables as reference parameters, HLA needs to compute the address of the object at run-time. This generally requires the use of the LEA instruction. Unfortunately, the LEA instruction requires the use of a 32-bit register and HLA promises not to disturb the values in any registers when it automatically generates code for you7. Therefore, HLA needs to preserve the value in whatever register it uses when it computes an address via LEA to pass a parameter by reference. The following example shows you the code that HLA actually emits:
// Call to the HasRefParm procedure: HasRefParm( v ); // HLA actually emits the following code for the above call: push( eax ); push( eax ); lea( eax, v ); mov( eax, [esp+4] ); pop( eax ); call HasRefParm;As you can see, this is quite a bit of code, especially if you have a 32-bit register available and you don't need to preserve that register's value. Here's a better code sequence given the availability of EAX:
lea( eax, v ); push( eax ); call HasRefParm;Remember, when passing an actual parameter by reference, you must compute the address of that object and push the address onto the stack. For simple static objects you can use the address-of operator ("&") to easily compute the address of the object and push it onto the stack; however, for indexed and automatic objects, you will probably need to use the LEA instruction to compute the address of the object. Here are some examples that demonstrate this using the HasRefParm procedure from the previous examples:
static i: int32; Ary: int32[16]; iptr: pointer to int32 := &i; var v: int32; AV: int32[10]; vptr: pointer to int32; . . . lea( eax, v ); mov( eax, vptr ); . . . // HasRefParm( i ); push( &i ); // Simple static object, so just use "&". call HasRefParm; // HasRefParm( Ary[ebx] ); // Pass element of Ary by reference. lea( eax, Ary[ ebx*4 ]); // Must use LEA for indexed addresses. push( eax ); call HasRefParm; // HasRefParm( *iptr ); -- Pass object pointed at by iptr push( iptr ); // Pass address (iptr's value) on stack. call HasRefParm; // HasRefParm( v ); lea( eax, v ); // Must use LEA to compute the address push( eax ); // of automatic vars passed on stack. call HasRefParm; // HasRefParm( AV[ esi ] ); -- Pass element of AV by reference. lea( eax, AV[ esi*4] ); // Must use LEA to compute address of the push( eax ); // desired element. call HasRefParm; // HasRefParm( *vptr ); -- Pass address held by vptr... push( vptr ); // Just pass vptr's value as the specified call HasRefParm; // address.If you have an extra register to spare, you can tell HLA to use that register when computing the address of reference parameters (without emitting the code to preserve that register's value). The @USE option will tell HLA that it's okay to use the specified register without preserving it's value. As noted in the section on value parameters, the syntax for this procedure option is
@use reg32;where reg32 may be any of EAX, EBX, ECX, EDX, ESI, or EDI. Since reference parameters always pass a 32-bit value, all of these registers are equivalent as far as HLA is concerned (unlike value parameters, that may prefer the EAX, EBX, ECX, or EDX register). Your best choice would be EAX if the procedure is not passing a parameter in the EAX register and the procedure is returning a function result in EAX; otherwise, any currently unused register will work fine.
With the "@USE EAX;" option, HLA emits the shorter code given in the previous examples. It does not emit all the extra instructions needed to preserve EAX's value. This makes your code much more efficient, especially when passing several parameters by reference or when calling procedures with reference parameters several times.
3.8.5.5 Passing Formal Parameters as Actual Parameters
The examples in the previous two sections show how to pass static and automatic variables as parameters to a procedure, either by value or by reference. There is one situation that these sections don't handle properly: the case when you are passing a formal parameter in one procedure as an actual parameter to another procedure. The following simple example demonstrates the different cases that can occur for pass by value and pass by reference parameters:
procedure p1( val v:dword; var r:dword ); begin p1; . . . end p1; procedure p2( val v2:dword; var r2:dword ); begin p2; p1( v2, r2 ); // (1) First call to p1. p1( r2, v2 ); // (2) Second call to p1. end p2;In the statement labelled (1) above, procedure p2 calls procedure p1 and passes its two formal parameters as parameters to p1. Note that this code passes the first parameter of both procedures by value and it passes the second parameter of both procedures by reference. Therefore, in statement (1), the program passes the v2 parameter into p2 by value and passes it on to p1 by value; likewise, the program passes r2 in by reference and it passes the value onto p2 by reference.
Since p2's caller passes v2 in by value and p2 passes this parameter to p1 by value, all the code needs to do is make a copy of v2's value and pass this on to p1. The code to do this is nothing more than a single push instruction, e.g.,
push( v2 ); << code to handle r2 >> call p1;As you can see, this code is identical to passing an automatic variable by value. Indeed, it turns out that the code you need to write to pass a value parameter to another procedure is identical to the code you would write to pass a local, automatic, variable to that other procedure.
Passing r2 in statement (1) above requires a little more thought. You do not take the address of r2 using the LEA instruction as you would a value parameter or an automatic variable. When passing r2 on through to p1, the author of this code probably expects the r formal parameter to contain the address of the variable whose address p2's caller passed into p2. In plain English, this means that p2 must pass the address of r2's actual parameter on through to p1. Since the r2 parameter is actually a double word value containing the address of the corresponding actual parameter, this means that the code must pass the dword value of r2 on to p1. The complete code for statement (1) above looks like the following:
push( v2 ); // Pass the value passed in through v2 to p1. push( r2 ); // Pass the address passed in through r2 to p1. call p1;The important thing to note in this example is that passing a formal reference parameter (r2) as an actual reference parameter (r) does not involve taking the address of the formal parameter (r2). P2's caller has already done this; p2 need only pass this address on through to p1.
In the second call to p1 in the example above (2), the code swaps the actual parameters so that the call to p1 passes r2 by value and v2 by reference. Specifically, p1 expects p2 to pass it the value of the dword object associated with r2; likewise, it expects p2 to pass it the address of the value associated with v2.
To pass the value of the object associated with r2, your code must dereference the pointer associated with r2 and directly pass the value. Here is the code HLA automatically generates to pass r2 as the first parameter to p1 in statement (2):
sub( 4, esp ); // Make room on stack for parameter. push( eax ); // Preserve EAX's value. mov( r2, eax ); // Get address of object passed in to p2. mov( [eax], eax ); // Dereference to get the value of this object. mov( eax, [esp+4]);// Put value of parameter into its location on stack. pop( eax ); // Restore original EAX value.As usual, HLA generates a little more code than may be necessary because it won't destroy the value in the EAX register (you may use the @USE procedure option to tell HLA that it's okay to use EAX's value, thereby reducing the code it generates). You can write more efficient code if a register is available to use in this sequence. If EAX is unused, you could trim this down to the following:
mov( r2, eax ); // Get the pointer to the actual object. pushd( [eax] ); // Push the value of the object onto the stack.Since you can treat value parameters exactly like local (automatic) variables, you use the same code to pass v2 by reference to p1 as you would to pass a local variable in p2 to p1. Specifically, you use the LEA instruction to compute the address of the value in the v2. The code HLA automatically emits for statement (2) above preserves all registers and takes the following form (same as passing an automatic variable by reference):
push( eax ); // Make room for the parameter. push( eax ); // Preserve EAX's value. lea( eax, v2 ); // Compute address of v2's value. mov( eax, [esp+4]);// Store away address as parameter value. pop( eax ); // Restore EAX's valueOf course, if you have a register available, you can improve on this code. Here's the complete code that corresponds to statement (2) above:
mov( r2, eax ); // Get the pointer to the actual object. pushd( [eax] ); // Push the value of the object onto the stack. lea( eax, v2 ); // Push the address of V2 onto the stack. push( eax ); call p1;3.8.5.6 HLA Hybrid Parameter Passing Facilities
Like control structures, HLA provides a high level language syntax for procedure calls that is convenient to use and easy to read. However, this high level language syntax is sometimes inefficient and may not provide the capabilities you need (for example, you cannot specify an arithmetic expression as a value parameter as you can in high level languages). HLA lets you overcome these limitations by writing low-level ("pure") assembly language code. Unfortunately, the low-level code is harder to read and maintain than procedure calls that use the high level syntax. Furthermore, it's quite possible that HLA generates perfectly fine code for certain parameters and only one or two parameters present a problem. Fortunately, HLA provides a hybrid syntax for procedure calls that allows you to use both high-level and low-level syntax as appropriate for a given actual parameter. This lets you use the high level syntax where appropriate and then drop down into pure assembly language to pass those special parameters that HLA's high level language syntax cannot handle efficiently (if at all).
Within an actual parameter list (using the high level language syntax), if HLA encounters "#{" followed by a sequence of statements and a closing "}#", HLA will substitute the instructions between the braces in place of the code it would normally generate for that parameter. For example, consider the following code fragment:
procedure HybridCall( i:uns32; j:uns32 ); begin HybridCall; . . . end HybridCall; . . . // Equivalent to HybridCall( 5, i+j ); HybridCall ( 5, #{ mov( i, eax ); add( j, eax ); push( eax ); }# );The call to HybridCall immediately above is equivalent to the following "pure" assembly language code:
pushd( 5 ); mov( i, eax ); add( j, eax ); push( eax ); call HybridCall;As a second example, consider the example from the previous section:
procedure p2( val v2:dword; var r2:dword ); begin p2; p1( v2, r2 ); // (1) First call to p1. p1( r2, v2 ); // (2) Second call to p1. end p2;HLA generates exceedingly mediocre code for the second call to p1 in this example. If efficiency is important in the context of this procedure call, and you have a free register available, you might want to rewrite this code as follows8:
procedure p2( val v2:dword; var r2:dword ); begin p2; p1( v2, r2 ); // (1) First call to p1. p1 // (2) Second call to p1. ( // This code assumes EAX is free. #{ mov( r2, eax ); pushd( [eax] ); }#, #{ lea( eax, v2 ); push( eax ); }# ); end p2;3.8.5.7 Mixing Register and Stack Based Parameters
You can mix register parameters and standard (stack-based) parameters in the same high level procedure declaration, e.g.,
procedure HasBothRegAndStack( var dest:dword in edi; count:un32 );When constructing the activation record, HLA ignores the parameters you pass in registers and only processes those parameters you pass on the stack. Therefore, a call to the HasBothRegAndStack procedure will push only a single parameter onto the stack (count). It will pass the dest parameter in the EDI register. When this procedure returns to its caller, it will only remove four bytes of parameter data from the stack.
Note that when you pass a parameter in a register, you should avoid specifying that same register in the @USE procedure option. In the example above, HLA might not generate any code whatsoever at all for the dest parameter (because the value is already in EDI). Had you specified "@use edi;" and HLA decided it was okay to disturb EDI's value, this would destroy the parameter value in EDI; that won't actually happen in this particular example (since HLA never uses a register to pass a dword value parameter like count), but keep this problem in mind.
1The choice of instructions is dictated by whether x is a static variable (MOV for static objects, LEA for other objects).
2Especially if the parameter list changes frequently.
3Assuming, of course, that you don't instruct HLA otherwise. It is possible to tell HLA to reverse the order of the parameters on the stack. See the chapter on "Mixed Language Programming" for more details.
4Note that if you use the EXIT statement to exit a procedure, you must duplicate the code to pop the register values and place this code immediately before the EXIT clause. This is a good example of a maintenance nightmare and is also a good reason why you should only have one exit point in your program.
5This only applies if you use the HLA high level language syntax to declare and access parameters in your procedures. Of course, if you manually push the parameters yourself and you access the parameters inside the procedure using an addressing mode like "[ebp+8]" then you can pass any sized object you choose. Of course, keep in mind that most operating systems expect the stack to be dword-aligned, so parameters you push should be a multiple of four bytes long.
6Or better yet, pass the parameter directly in the register if you are writing the procedure yourself.
7This isn't entirely true. You'll see the exception in the chapter on Classes and Objects. Also, using the @USE procedure option tells HLA that it's okay to modify the value in one of the registers.
8Of course, you could also use the "@use eax;" procedure option to achieve the same effect in this example.
|