
Chapter Four Advanced Arithmetic
4.1 Chapter Overview
This chapter deals with those arithmetic operations for which assembly language is especially well suited and high level languages are, in general, poorly suited. It covers three main topics: extended precision arithmetic, arithmetic on operands who sizes are different, and decimal arithmetic.
By far, the most extensive subject this chapter covers is multi-precision arithmetic. By the conclusion of this chapter you will know how to apply arithmetic and logical operations to integer operands of any size. If you need to work with integer values outside the range ±2 billion (or with unsigned values beyond four billion), no sweat; this chapter will show you how to get the job done.
Operands whose sizes are not the same also present some special problems in arithmetic operations. For example, you may want to add a 128-bit unsigned integer to a 256-bit signed integer value. This chapter discusses how to convert these two operands to a compatible format so the operation may proceed.
Finally, this chapter discusses decimal arithmetic using the BCD (binary coded decimal) features of the 80x86 instruction set and the FPU. This lets you use decimal arithmetic in those few applications that absolutely require base 10 operations (rather than binary).
4.2 Multiprecision Operations
One big advantage of assembly language over high level languages is that assembly language does not limit the size of integer operations. For example, the C programming language defines a maximum of three different integer sizes: short int, int, and long int1. On the PC, these are often 16 and 32 bit integers. Although the 80x86 machine instructions limit you to processing eight, sixteen, or thirty-two bit integers with a single instruction, you can always use more than one instruction to process integers of any size you desire. If you want to add 256 bit integer values together, no problem, it's relatively easy to accomplish this in assembly language. The following sections describe how extended various arithmetic and logical operations from 16 or 32 bits to as many bits as you please.
4.2.1 Multiprecision Addition Operations
The 80x86 ADD instruction adds two eight, sixteen, or thirty-two bit numbers2. After the execution of the add instruction, the 80x86 carry flag is set if there is an overflow out of the H.O. bit of the sum. You can use this information to do multiprecision addition operations. Consider the way you manually perform a multidigit (multiprecision) addition operation:
Step 1: Add the least significant digits together: 289 289 +456 produces +456 ---- ---- 5 with carry 1. Step 2: Add the next significant digits plus the carry: 1 (previous carry) 289 289 +456 produces +456 ---- ---- 5 45 with carry 1. Step 3: Add the most significant digits plus the carry: 1 (previous carry) 289 289 +456 produces +456 ---- ---- 45 745The 80x86 handles extended precision arithmetic in an identical fashion, except instead of adding the numbers a digit at a time, it adds them together a byte, word, or dword at a time. Consider the three double word (96 bit) addition operation in Figure 4.1.
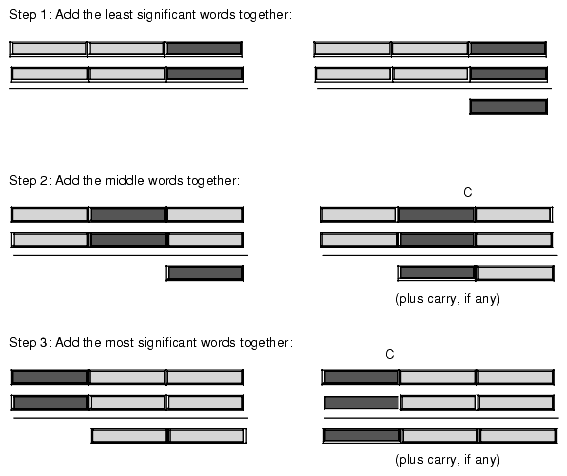
Figure 4.1 Adding Two 96-bit Objects Together
As you can see from this figure, the idea is to break up a larger operation into a sequence of smaller operations. Since the x86 processor family is capable of adding together, at most, 32 bits at a time, the operation must proceed in blocks of 32-bits or less. So the first step is to add the two L.O. double words together much as we would add the two L.O. digits of a decimal number together in the manual algorithm. There is nothing special about this operation, you can use the ADD instruction to achieve this.
The second step involves adding together the second pair of double words in the two 96-bit values. Note that in step two, the calculation must also add in the carry out of the previous addition (if any). If there was a carry out of the L.O. addition, the ADD instruction sets the carry flag to one; conversely, if there was no carry out of the L.O. addition, the earlier ADD instruction clears the carry flag. Therefore, in this second addition, we really need to compute the sum of the two double words plus the carry out of the first instruction. Fortunately, the x86 CPUs provide an instruction that does exactly this: the ADC (add with carry) instruction. The ADC instruction uses the same syntax as the ADD instruction and performs almost the same operation:
adc( source, dest ); // dest := dest + source + CAs you can see, the only difference between the ADD and ADC instruction is that the ADC instruction adds in the value of the carry flag along with the source and destination operands. It also sets the flags the same way the ADD instruction does (including setting the carry flag if there is an unsigned overflow). This is exactly what we need to add together the middle two double words of our 96-bit sum.
In step three of Figure 4.1, the algorithm adds together the H.O. double words of the 96-bit value. Once again, this addition operation also requires the addition of the carry out of the sum of the middle two double words; hence the ADC instruction is needed here, as well. To sum it up, the ADD instruction adds the L.O. double words together. The ADC (add with carry) instruction adds all other double word pairs together. At the end of the extended precision addition sequence, the carry flag indicates unsigned overflow (if set), a set overflow flag indicates signed overflow, and the sign flag indicates the sign of the result. The zero flag doesn't have any real meaning at the end of the extended precision addition (it simply means that the sum of the H.O. two double words is zero, this does not indicate that the whole result is zero).
For example, suppose that you have two 64-bit values you wish to add together, defined as follows:
static X: qword; Y: qword;Suppose, also, that you want to store the sum in a third variable, Z, that is likewise defined with the qword type. The following x86 code will accomplish this task:
mov( (type dword X), eax ); // Add together the L.O. 32 bits add( (type dword Y), eax ); // of the numbers and store the mov( eax, (type dword Z) ); // result into the L.O. dword of Z. mov( (type dword X[4]), eax ); // Add together (with carry) the adc( (type dword Y[4]), eax ); // H.O. 32 bits and store the result mov( eax, (type dword Z[4]) ); // into the H.O. dword of Z.Remember, these variables are qword objects. Therefore the compiler will not accept an instruction of the form "mov( X, eax );" because this instruction would attempt to load a 64 bit value into a 32 bit register. This code uses the coercion operator to coerce symbols X, Y, and Z to 32 bits. The first three instructions add the L.O. double words of X and Y together and store the result at the L.O. double word of Z. The last three instructions add the H.O. double words of X and Y together, along with the carry out of the L.O. word, and store the result in the H.O. double word of Z. Remember, address expressions of the form "X[4]" access the H.O. double word of a 64 bit entity. This is due to the fact that the x86 address space addresses bytes and it takes four consecutive bytes to form a double word.
You can extend this to any number of bits by using the ADC instruction to add in the higher order words in the values. For example, to add together two 128 bit values, you could use code that looks something like the following:
type tBig: dword[4]; // Storage for four dwords is 128 bits. static BigVal1: tBig; BigVal2: tBig; BigVal3: tBig; . . . mov( BigVal1[0], eax ); // Note there is no need for (type dword BigValx) add( BigVal2[0], eax ); // because the base type of BitValx is dword. mov( eax, BigVal3[0] ); mov( BigVal1[4], eax ); adc( BigVal2[4], eax ); mov( eax, BigVal3[4] ); mov( BigVal1[8], eax ); adc( BigVal2[8], eax ); mov( eax, BigVal3[8] ); mov( BigVal1[12], eax ); adc( BigVal2[12], eax ); mov( eax, BigVal3[12] );4.2.2 Multiprecision Subtraction Operations
Like addition, the 80x86 performs multi-byte subtraction the same way you would manually, except it subtracts whole bytes, words, or double words at a time rather than decimal digits. The mechanism is similar to that for the ADD operation, You use the SUB instruction on the L.O. byte/word/double word and the SBB (subtract with borrow) instruction on the high order values. The following example demonstrates a 64 bit subtraction using the 32 bit registers on the x86:
static Left: qword; Right: qword; Diff: qword; . . . mov( (type dword Left), eax ); sub( (type dword Right), eax ); mov( eax, (type dword Diff) ); mov( (type dword Left[4]), eax ); sbb( (type dword Right[4]), eax ); mov( (type dword Diff[4]), eax );The following example demonstrates a 128-bit subtraction:
type tBig: dword[4]; // Storage for four dwords is 128 bits. static BigVal1: tBig; BigVal2: tBig; BigVal3: tBig; . . . // Compute BigVal3 := BigVal1 - BigVal2 mov( BigVal1[0], eax ); // Note there is no need for (type dword BigValx) sub( BigVal2[0], eax ); // because the base type of BitValx is dword. mov( eax, BigVal3[0] ); mov( BigVal1[4], eax ); sbb( BigVal2[4], eax ); mov( eax, BigVal3[4] ); mov( BigVal1[8], eax ); sbb( BigVal2[8], eax ); mov( eax, BigVal3[8] ); mov( BigVal1[12], eax ); sbb( BigVal2[12], eax ); mov( eax, BigVal3[12] );4.2.3 Extended Precision Comparisons
Unfortunately, there isn't a "compare with borrow" instruction that you can use to perform extended precision comparisons. Since the CMP and SUB instructions perform the same operation, at least as far as the flags are concerned, you'd probably guess that you could use the SBB instruction to synthesize an extended precision comparison; however, you'd only be partly right. There is, however, a better way.
Consider the two unsigned values $2157 and $1293. The L.O. bytes of these two values do not affect the outcome of the comparison. Simply comparing $21 with $12 tells us that the first value is greater than the second. In fact, the only time you ever need to look at both bytes of these values is if the H.O. bytes are equal. In all other cases comparing the H.O. bytes tells you everything you need to know about the values. Of course, this is true for any number of bytes, not just two. The following code compares two unsigned 64 bit integers:
// This sequence transfers control to location "IsGreater" if // QwordValue > QwordValue2. It transfers control to "IsLess" if // QwordValue < QwordValue2. It falls though to the instruction // following this sequence if QwordValue = QwordValue2. To test for // inequality, change the "IsGreater" and "IsLess" operands to "NotEqual" // in this code. mov( (type dword QWordValue[4]), eax ); // Get H.O. dword cmp( eax, (type dword QWordValue2[4])); jg IsGreater; jl IsLess; mov( (type dword QWordValue[0]), eax ); // If H.O. dwords were equal, cmp( eax, (type dword QWordValue2[0])); // then we must compare the ja IsGreater; // L.O. dwords. jb IsLess; // Fall through to this point if the two values were equal.To compare signed values, simply use the JG and JL instructions in place of JA and JB for the H.O. words (only). You must continue to use unsigned comparisons for all but the H.O. double words you're comparing.
You can easily synthesize any possible comparison from the sequence above, the following examples show how to do this. These examples demonstrate signed comparisons, substitute JA, JAE, JB, and JBE for JG, JGE, JL, and JLE (respectively) for the H.O. comparisons if you want unsigned comparisons.
static QW1: qword; QW2: qword; const QW1d: text := "(type dword QW1)"; QW2d: text := "(type dword QW2)"; // 64 bit test to see if QW1 < QW2 (signed). // Control transfers to "IsLess" label if QW1 < QW2. Control falls // through to the next statement (at "NotLess") if this is not true. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jg NotLess; // Substitute ja here for unsigned comparison. jl IsLess; // Substitute jb here for unsigned comparison. mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); jb IsLess; NotLess: // 64 bit test to see if QW1 <= QW2 (signed). Jumps to "IsLessEq" if the // condition is true. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jg NotLessEQ; // Substitute ja here for unsigned comparison. jl IsLessEQ; // Substitute jb here for unsigned comparison. mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); jbe IsLessEQ; NotLessEQ: // 64 bit test to see if QW1 > QW2 (signed). Jumps to "IsGtr" if this condition // is true. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jg IsGtr; // Substitute ja here for unsigned comparison. jl NotGtr; // Substitute jb here for unsigned comparison. mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); ja IsGtr; NotGtr: // 64 bit test to see if QW1 >= QW2 (signed). Jumps to "IsGtrEQ" if this // is the case. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jg IsGtrEQ; // Substitute ja here for unsigned comparison. jl NotGtrEQ; // Substitute jb here for unsigned comparison. mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); jae IsGtrEQ; NotGtrEQ: // 64 bit test to see if QW1 = QW2 (signed or unsigned). This code branches // to the label "IsEqual" if QW1 = QW2. It falls through to the next instruction // if they are not equal. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jne NotEqual; mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); je IsEqual; NotEqual: // 64 bit test to see if QW1 <> QW2 (signed or unsigned). This code branches // to the label "NotEqual" if QW1 <> QW2. It falls through to the next // instruction if they are equal. mov( QW1d[4], eax ); // Get H.O. dword cmp( eax, QW2d[4] ); jne NotEqual; mov( QW1d[0], eax ); // Fall through to here if the H.O. dwords are equal. cmp( eax, QW2d[0] ); jne NotEqual; // Fall through to this point if they are equal.You cannot directly use the HLA high level control structures if you need to perform an extended precision comparison. However, you may use the HLA hybrid control structures and bury the appropriate comparison into this statements. Doing so will probably make your code easier to read. For example, the following if..then..else..endif statement checks to see if QW1 > QW2 using a 64-bit extended precision signed comparison:
if ( #{ mov( QW1d[4], eax ); cmp( eax, QW2d[4] ); jg true; mov( QW1d[0], eax ); cmp( eax, QW2d[0] ); jna false; }# ) then << code to execute if QW1 > QW2 >> else << code to execute if QW1 <= QW2 >> endif;If you need to compare objects that are larger than 64 bits, it is very easy to generalize the code above. Always start the comparison with the H.O. double words of the objects and work you way down towards the L.O. double words of the objects as long as the corresponding double words are equal The following example compares two 128-bit values to see if the first is less than or equal (unsigned) to the second:
type t128: dword[4]; static Big1: t128; Big2: t128; . . . if ( #{ mov( Big1[12], eax ); cmp( eax, Big2[12] ); jb true; mov( Big1[8], eax ); cmp( eax, Big2[8] ); jb true; mov( Big1[4], eax ); cmp( eax, Big2[4] ); jb true; mov( Big1[0], eax ); cmp( eax, Big2[0] ); jnbe false; }# ) then << Code to execute if Big1 <= Big2 >> else << Code to execute if Big1 > Big2 >> endif;1Newer C standards also provide for a "long long int" which is usually a 64-bit integer.
2As usual, 32 bit arithmetic is available only on the 80386 and later processors.
|