
Chapter Eleven The MMX Instruction Set
11.1 Chapter Overview
While working on the Pentium and Pentium Pro processors, Intel was also developing an instruction set architecture extension for multimedia applications. By studying several existing multimedia applications, developing lots of multimedia related algorithms, and through simulation, Intel developed 57 instructions that would greatly accelerate the execution of multimedia applications. The end result was their multimedia extensions to the Pentium processor that Intel calls the MMX Technology Instructions.
Prior to the invention of the MMX enhancements, good quality multimedia systems required separate digital signal processors and special electronics to handle much of the multimedia workload1. The introduction of the MMX instruction set allowed later Pentium processors to handle these multimedia tasks without these expensive digital signal processors (DSPs), thus lowering the cost of multimedia systems. So later Pentiums, Pentium II, Pentium III, and Pentium IV processors all have the MMX instruction set. Earlier Pentiums (and CPUs prior to the Pentium) and the Pentium Pro do not have these instructions available. Since the instruction set has been available for quite some time, you can probably use the MMX instructions without worrying about your software failing on many machines.
In this chapter we will discuss the MMX Technology instructions and how to use them in your assembly language programs. The use of MMX instructions, while not completely limited to assembly language, is one area where assembly language truly shines since most high level languages do not make good use of MMX instructions except in library routines. Therefore, writing fast code that uses MMX instructions is mainly the domain of the assembly language programmer. Hence, it's a good idea to learn these instructions if you're going to write much assembly code.
11.2 Determining if a CPU Supports the MMX Instruction Set
While it's almost a given that any modern CPU your software will run on will support the MMX extended instruction set, there may be times when you want to write software that will run on a machine even in the absence of MMX instructions. There are two ways to handle this problem - either provide two versions of the program, one with MMX support and one without (and let the user choose which program they wish to run), or the program can dynamically determine whether a processor supports the MMX instruction set and skip the MMX instructions if they are not available.
The first situation, providing two different programs, is the easiest solution from a software development point of view. You don't actually create two source files, of course; what you do is use conditional compilation statements (i.e., #IF..#ELSE..#ENDIF) to selectively compile MMX or standard instructions depending on the presence of an identifier or value of a boolean constant in your program. See "Conditional Compilation (Compile-Time Decisions)" on page 962 for more details.
Another solution is to dynamically determine the CPU type at run-time and use program logic to skip over the MMX instructions and execute equivalent standard code if the CPU doesn't support the MMX instruction set. If you're expecting the software to run on an Intel Pentium or later CPU, you can use the CPUID instruction to determine whether the processor supports the MMX instruction set . If MMX instructions are available, the CPUID instruction will return bit 23 as a one in the feature flags return result.
The following code illustrates how to use the CPUID instruction. This example does not demonstrate the entire CPUID sequence, but shows the portion used for detection of MMX technology.
// For a perfectly general routine, you should determine if this // is a Pentium or later processor. We'll assume at least a Pentium // for now, since most OSes expect a Pentium or better processor. mov( 1, eax ); // Request for CPUID feature flags. CPUID(); // Get the feature flags into EDX. test( $80_0000, edx ); // Is bit 23 set? jnz HasMMX;This code assumes at least the presence of a Pentium Processor. If your code needs to run on a 486 or 386 processor, you will have to detect that the system is using one of these processors. There is tons of code on the net that detects different processors, but most of it will not run under 32-bit OSes since the code typically uses protected (non-user-mode) instructions. Some operating system provide a system call or environment variable that will specify the CPU. We'll not go into the details here because 99% of the users out there that are running modern operating systems have a CPU that supports the MMX instruction set or, at least, the CPUID instruction.
11.3 The MMX Programming Environment
The MMX architecture extends the Pentium architecture by adding the following:
- Eight MMX registers (MM0..MM7).
- Four MMX data types (packed bytes, packed words, packed double words, and quad word).
- 57 MMX Instructions.
11.3.1 The MMX Registers
The MMX architecture adds eight 64-bit registers to the Pentium. The MMX instructions refer to these registers as MM0, MM1, MM2, MM3, MM4, MM5, MM6, and MM7. These are strictly data registers, you cannot use them to hold addresses nor are they suitable for calculations involving addresses.
Although MM0..MM7 appear as separate registers in the Intel Architecture, the Pentium processors alias these registers with the FPU's registers (ST0..ST7). Each of the eight MMX 64-bit registers is physically equivalent to the L.O. 64-bits of each of the FPU's registers (see Figure 11.1). The MMX registers overlay the FPU registers in much the same way that the 16-bit general purpose registers overlay the 32-bit general purpose registers.
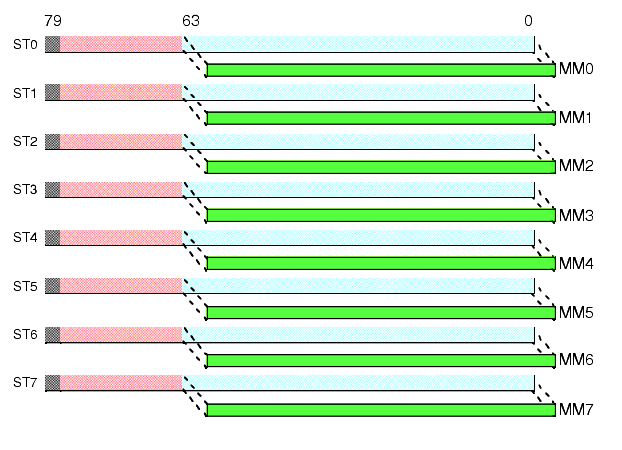
Figure 11.1 MMX and FPU Register Aliasing
Because the MMX registers overlay the FPU registers, you cannot mix FPU and MMX instructions in the same computation sequence. You can begin executing an MMX instruction sequence at any time; however, once you execute an MMX instruction you cannot execute another FPU instruction until you execute a special MMX instruction, EMMS (Exit MMX Machine State). This instruction resets the FPU so you may begin a new sequence of FPU calculations. The CPU does not save the FPU state across the execution of the MMX instructions; executing EMMS clears all the FPU registers. Because saving FPU state is very expensive, and the EMMS instruction is quite slow, it's not a good idea to frequently switch between MMX and FPU calculations. Instead, you should attempt to execute the MMX and FPU instructions at different times during your program's execution.
You're probably wondering why Intel chose to alias the MMX registers with the FPU registers. Intel, in their literature, brags constantly about what a great idea this was. You see, by aliasing the MMX registers with the FPU registers, Microsoft and other multitasking OS vendors did not have to write special code to save the MMX state when the CPU switched from one process to another. The fact that the OS automatically saved the FPU state means that the CPU would automatically save the MMX state as well. This meant that the new Pentium chips with MMX technology that Intel created were automatically compatible with Windows 95, Windows NT, and Linux without any changes to the operating system code.
Of course, those operating systems have long since been upgraded and Microsoft (and Linux developers) could have easily provided a "service pack" to handle the new registers (had Intel chosen not to alias the FPU and MMX registers). So while aliasing MMX with the FPU provided a very short-lived and temporary benefit, in retrospect Intel made a big mistake with this decision. They've obviously realized their mistake, because as they've introduced new "streaming" instructions (the floating point equivalent of the MMX instruction set) they've added new registers (XMM0..XMM7) without using this trick. It's too bad they don't fix the problem in their current CPUs (there is no technical reason why they can't create separate MMX and FPU registers at this point). Oh well, you'll just have to live with the fact that you can't execute interleaved FPU and MMX instructions.
11.3.2 The MMX Data Types
The MMX instruction set supports four different data types: an eight-byte array, a four-word array, a two element double word array, and a quadword object. Each MMX register processes one of these four data types (see Figure 11.2).
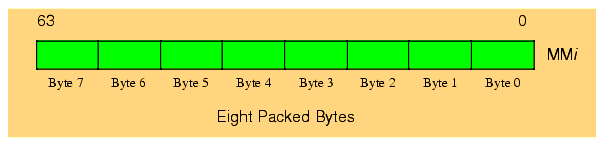
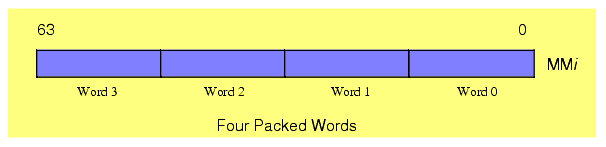
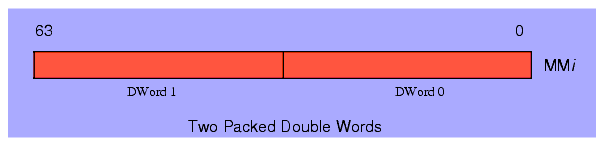
Figure 11.2 The MMX Data Types
Despite the presence of 64-bit registers, the MMX instruction set does not extend the 32-bit Pentium processor to 64-bits. Instead, after careful study Intel added only those 64-bit instructions that were useful for multimedia operations. For example, you cannot add or subtract two 64-bit integers with the MMX instruction set. In fact, only the logical and shift operations directly manipulate 64 bits.
The MMX instruction set was not designed to provide general 64-bit capabilities to the Pentium. Instead, the MMX instruction set provides the Pentium with the capability of performing multiple eight-, sixteen-, or thirty-two bit operations simultaneously. In other words, the MMX instructions are generally SIMD (Single Instruction Multiple Data) instructions (see "Parallel Processing" on page 268 for an explanation of SIMD). For example, a single MMX instruction can add eight separate pairs of byte values together. This is not the same as adding two 64-bit values since the overflow from the individual bytes does not carry over into the higher order bytes. This can accelerate a program that needs to add a long string of bytes together since a single MMX instruction can do the work of eight regular Pentium instructions. This is how the MMX instruction set speeds up multimedia applications - by processing multiple data objects in parallel with a single instruction. Given the data types the MMX instruction set supports, you can process up to eight byte objects in parallel, four word objects in parallel, or two double words in parallel.
11.4 The Purpose of the MMX Instruction Set
The Single Instruction Multiple Data model the MMX architecture supports may not look all that impressive when viewed with a SISD (Single Instruction, Single Data) bias. Once you've mastered the basic integer instructions on the 80x86, it's difficult to see the application of the MMX's SIMD instruction set. However, the MMX instructions directly address the needs of modern media, communications, and graphics applications, which often use sophisticated algorithms that perform the same operations on a large number of small data types (bytes, words, and double words).
For example, most programs use a stream of bytes or words to represent audio and video data. The MMX instructions can operate on eight bytes or four words with a single instruction, thus accelerating the program by almost a factor of four or eight.
One drawback to the MMX instruction set is that it is not general purpose. Intel's research that led to the development of these new instructions specifically targeted audio, video, graphics, and another multimedia applications. Although some of the instructions are applicable in many general programs, you'll find that many of the instructions have very little application outside their limited domain. Although, with a lot of deep thought, you can probably dream up some novel uses of many of these instructions that have nothing whatsoever at all to do with multimedia, you shouldn't get too frustrated if you cannot figure out why you would want to use a particular instruction; that instruction probably has a specific purpose and if you're not trying to code a solution for that problem, you may not be able to use the instruction. If you're questioning why Intel would put such limited instructions in their instruction set, just keep in mind that although you can use the instruction(s) for lots of different purposes, they are invaluable for the few purposes they are uniquely suited.
11.5 Saturation Arithmetic and Wraparound Mode
The MMX instruction set supports saturating arithmetic (see "Sign Extension, Zero Extension, Contraction, and Saturation" on page 73). When manipulating standard integer values and an overflow occurs, the standard integer instructions maintain the correct L.O. bits of the value in the integer while truncating any overflow2. This form of arithmetic is known as wraparound mode since the L.O. bits wrap back around to zero. For example, if you add the two eight-bit values $02 and $FF you wind up with a carry and the result $01. The actual sum is $101, but the operation truncates the ninth bit and the L.O. byte wraps around to $01.
In saturation mode, results of an operation that overflow or underflow are clipped (saturated) to some maximum or minimum value depending on the size of the object and whether it is signed or unsigned. The result of an operation that exceeds the range of a data-type saturates to the maximum value of the range. A result that is less than the range of a data type saturates to the minimum value of the range.
For example, when the result exceeds the data range limit for signed bytes, it is saturated to $7f; if a value is less than the data range limit, it is saturated to $80 for signed bytes. If a value exceeds the range for unsigned bytes, it is saturated to $ff or $00.
This saturation effect is very useful for audio and video data. For example, if you are amplifying an audio signal by multiplying the words in the CD-quality 44.1 kHz audio stream by 1.5, clipping the value at +32767, while introducing distortion, sounds far better than allowing the waveform to wrap around to -32768. Similarly, if you are mixing colors in a 24-bit graphic or video image, saturating to white produces much more meaningful results than wrap-around.
Since Intel created the MMX architecture to support audio, graphics, and video, it should come as no surprise that the MMX instruction set supports saturating arithmetic. For those applications that require saturating arithmetic, having the CPU automatically handle this process (rather than having to explicitly check after each calculation) is another way the MMX architecture speeds up multimedia applications.
11.6 MMX Instruction Operands
Most MMX instructions operate on two operands, a source and a destination operand. A few instructions have three operands with the third operand being a small immediate (constant) value. In this section we'll take a look at the common MMX instruction operands.
The destination operand is almost always an MMX register. In fact, the only exceptions are those instructions that store an MMX register into memory. The MMX instructions always leave the result of MMX calculations in an MMX register.
The source operand can be an MMX register or a memory location. The memory location is usually a quad word entity, but certain instructions operate on double word objects. Note that, in this context, "quad word" and "double word" mean eight or four consecutive bytes in memory; they do not necessarily imply that the MMX instruction is operating on a qword or dword object. For example, if you add eight bytes together using the PADDB (packed add bytes) instruction, PADDB references a qword object in memory, but actually adds together eight separate bytes.
For most MMX instructions, the generic HLA syntax is one of the following:
mmxInstr( source, dest );mmxInstr( mmi, mmi ); // i=0..7 mmxInstr( mem, mmi ); // i=0..7MMX instructions access memory using the same addressing modes as the standard integer instructions. Therefore, any legal 80x86 addressing mode is usable in an MMX instruction. For those instructions that reference a 64-bit memory location, HLA requires that you specify an anonymous memory object (e.g., "[ebx]" or "[ebp+esi*8+6]") or a qword variable.
A few instructions require a small immediate value (or constant). For example, the shift instructions let you specify a shift count as an immediate value in the range 0..63. Another instruction uses the immediate value to specify a set of four different count values in the range 0..3 (i.e., four two-bit count values). These instructions generally take the following form:
mmxInstr( imm8, source, dest );Note that, in general, MMX instructions do not allow you to specify immediate constants as operands except for a few special cases (such as shift counts). In particular, the source operand to an MMX instruction has to be a register or a quad word variable, it cannot be a 64-bit constant. To achieve the same effect as specifying a constant as the source operand, you must initialize a quad word variable in the READONLY (or STATIC) section of your program and specify this variable as the source operand. Unfortunately, HLA does not support 64-bit constants, so initializing the value is going to be a bit of a problem. There are two solutions to this problem: break the constant into smaller pieces (bytes, words, or double words) and emit the constant in pieces that HLA can process; or you can write your own numeric conversion routine(s) using the HLA compile-time language to allow the emission of a 64-bit constant. We'll explore both of those approaches here.
The first approach is the one you will most commonly use. Very few MMX instructions actually operate on 64-bit data operands; instead, they typically operate on a (small) array of bytes, words, or double words. Since HLA provides good support for byte, word, and double word constant expressions, specifying a 64-bit MMX memory operand as a short array of objects is probably the best way to create this data. Since the MMX instructions that fetch a source value from memory expect a 64-bit operand, you must declare such objects as qword variables, e.g.,
static mmxVar:qword;The big problem with this declaration is that the qword type does not allow an initializer (since HLA cannot handle 64-bit constant expressions). Since this declaration occurs in the STATIC segment, HLA will initialize mmxVar with zero; probably not the value you're interested in supplying here.
There are two ways to solve this problem. The first way is to attach the @NOSTORAGE option to the MMX variable declarations in the STATIC segment. The data declarations that immediately follow the variable definition provide the initial data for that variable. Here's an example of such a declaration:
static mmxDVar: qword; @nostorage; dword $1234_5678, $90ab_cdef;Note that the DWORD directive above stores the double word constants in successive memory locations. Therefore, $1234_5678 will appear in the L.O. double word of the 64-bit value and $90ab_cdef will appear in the H.O. double word of the 64-bit value. Always keep in mind that the L.O. objects come first in the list following the DWORD (or BYTE, or WORD, or ???) directive; this is opposite of the way you're used to reading 64-bit values.
The example above used a DWORD directive to provide the initialization constant. However, you can use any data declaration directive, or even a combination of directives, as long as you allocate at least eight bytes (64-bits) for each qword constant. The following data declaration, for example, initializes eight eight-bit constants for an MMX operand; this would be perfect for a PADDB instruction or some other instruction that operates on eight bytes in parallel:
static eightBytes: qword; @nostorage; byte 0, 1, 2, 3, 4, 5, 6, 7;Although most MMX instructions operate on small arrays of bytes, words, or double words, a few actually do operate on 64-bit quantities. For such memory operands you would probably prefer to specify a 64-bit constant rather than break it up into its constituent double word values. This way, you don't have to remember to put the L.O. double word first and perform other mental adjustments.
Although HLA does not support 64-bit constants in the compile time language, HLA is flexible enough to allow you to extend the language to handle such declarations. Program 11.1 demonstrates how to write a macro to accept a 64-bit hexadecimal constant. This macro will automatically emit two DWORD declarations containing the L.O. and H.O. components of the 64-bit value you specify as the qword16 (quadword constant, base 16) macro parameter. You would typically use the qword16 macro as follows:
static HOOnes: qword; @nostorage; qword16( $FFFF_FFFF_0000_0000 );The qword16 macro would emit the following:
dword 0; dword $FFFF_FFFF;Without further ado, here's the macro (and a sample test program):
program qwordConstType; #include( "stdlib.hhf" ) // The following macro accepts a 64-bit hexadecimal constant // and emits two dword objects in place of the constant. macro qword16( theHexVal ):hs, len, dwval, mplier, curch, didLO; // Remove whitespace around the macro parameter (shouldn't // be any, but just in case something weird is going on) and // convert all lower case characters to upper case. ?hs := @uppercase( @trim( @string:theHexVal, 0 ), 0); // If there is a leading "$" symbol, strip it from the string. #if( @substr( hs, 0, 1) = "$" ) ?hs := @substr( hs, 1, 256 ); #endif // Process each character in the string from the L.O. digit // through to the H.O. digit. Add the digit, multiplied by // some successive power of 16, to the current sum we're // accumulating in dwval. When we cross a dword boundary, // emit the L.O. dword and start over. ?len := @length( hs ); // Number of characters to process. ?dwval:dword := 0; // Accumulate value here. ?mplier:dword := 1; // Power of 16 to multiply by. ?didLO:boolean := false; // Checks for overflow. #while( len > 0 ) // Repeat for each char in string. // For each character in the string, verify that it is // a legal hexadecimal character and merge it in with the // current accumulated value if it is. Print an error message // if we come across an illegal character. ?len := len - 1; // Next available char. ?curch := char( @substr( hs, len, 1 )); // Get the character. #if( curch in {`0'..'9'} ) // See if valid decimal digit. // Accumulate result if decimal digit. ?dwval := dwval + (uns8( curch ) - uns8( `0' )) * mplier; #elseif( curch in {`A'..'F'} ) // See if valid hex digit. // Accumulate result if a hexadecimal digit. ?dwval := dwval + (uns8( curch ) - uns8( `A' ) + 10) * mplier; // Ignore underscore characters and report an error for anything // else we find in the string. #elseif( curch <> `_' ) #error( "Illegal character in 64-bit hexadecimal constant" ) #print( "Character = `", curch, "` Rest of string: `", hs, "`" ) #endif // If it's not an underscore character, adjust the multiplier value. // If we cross a dword boundary, emit the L.O. value as a dword // and reset everything for the H.O. dword. #if( curch <> `_' ) // If the current value fits in 32 bits, process this // as though it were a dword object. #if( mplier < $1000_0000 ) ?mplier := mplier * 16; #elseif( len > 0 ) // Down here we've just processed the last hex // digit that will fit into 32 bits. So emit the // L.O. dword and reset the mplier and dwval constants. ?mplier := 1; dword dwval; ?dwval := 0; // If we've been this way before, we've got an // overflow. #if( didLO ) #error( "64-bit overflow in constant" ); #endif ?didLO := true; #endif #endif #endwhile // Emit the H.O. dword here. dword dwval; // If the constant only consumed 32 bits, we've got to emit a zero // for the H.O. dword at this point. #if( !didLO ) dword 0; #endif endmacro; static x:qword; @nostorage; qword16( $1234_5678_90ab_cdef ); qword16( 100 ); begin qwordConstType; stdout.put( "64-bit value of x = $" ); stdout.putq( x ); stdout.newln(); end qwordConstType; Program 11.1 qword16 Macro to Process 64-bit Hexadecimal ConstantsAlthough it's a little bit more difficult, you could also write a qword10 macro that lets you specify decimal constants as the macro operand rather than hexadecimal constants. The implementation of qword10 is left as a programming exercise at the end of this volume.
1A good example was the Apple Quadra 660AV and 840AV computer systems; they were built around the Motorola 68040 processor rather than a Pentium, but the 68040 was no more capable of handling multimedia applications than the Pentium. However, an on-board DSP (digital signal processor) CPU allowed the Quadras to easily handle audio applications that the 68040 could not.
2For some instructions the overflow may appear in another register or the carry flag, but in the destination register the high order bits are lost.
|